Filtering external evidence for realistic training and evaluation of Automated Fact-Checking
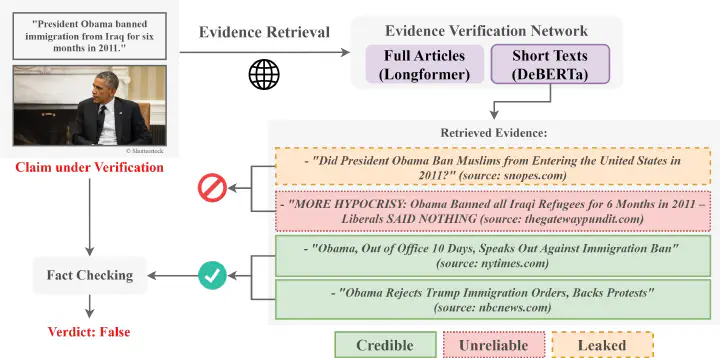 Pipeline of automated fact-checking leveraging the proposed Evidence Verification Network.
Pipeline of automated fact-checking leveraging the proposed Evidence Verification Network.
In this post, we explain the basics behind our paper Credible, Unreliable or Leaked?: Evidence verification for enhanced automated fact-checking by Zacharias Chrysidis, Stefanos-Iordanis Papadopoulos, Symeon Papadopoulos and Panagiotis C. Petrantonakis, which has been presented at ICMR’s 3rd ACM International Workshop on Multimedia AI against Disinformation.
Automated Fact-Checking (AFC)
The Information Age, especially after the explosion of online platforms and social media, has led to a surge in new forms of mis- and disinformation, making it increasingly difficult for people to trust what they see and read online. To combat this, many fact-checking organizations, including Snopes, PolitiFact as well as Reuters and AFP fact-checks, have emerged, dedicated to verifying claims in news articles and social media posts. Nevertheless, the manual process of fact-checking is time-consuming and can’t always keep pace with the rapid spread of mis- and disinformation. This is where the field of Automated Fact-Checking (AFC) comes in. In recent years, researchers have been trying to leverage advances in deep learning, large language models, computer vision, and multimodal learning to develop tools to assist the work of professional fact-checkers. AFC systems aim to automate key parts of the fact-checking process, such as detecting check-worthy claims, retrieving relevant evidence from the web, and cross-examining them against the claim (Guo, et al., 2022). Since fact-checking rarely relies solely on examining internal contradictions in claims, AFC systems often require the retrieval of external information from the web, knowledge databases, or performing inverse image searches to support or refute a claim, as shown below.

Challenges of training Automated Fact-Checking (AFC) systems
Nevertheless, in order to develop and train AFC systems that can be applied to real-world cases, the collected evidence should follow certain criteria, such as “[the evidence in datasets] must be (1) sufficient to refute the claim and (2) not leaked from existing fact-checking articles” as defined by Glockner et al., 2022. The problem of leaked evidence in AFC systems arises when information from previously fact-checked articles is used during training. This can lead the model to overly rely on high-quality information curated by professional fact-checkers, making it less effective at handling new and emerging misinformation that has not yet been fact-checked –which is supposedly the task at hand. Additionally, the external information retrieved by the model must be credible to avoid feeding it with unreliable and false data. For example, as shown in the banner of this article, the retrieved evidence “Did President Obama Ban Muslims from Entering the United States in 2011?” is sourced from Snopes, thus, using the full article would allow leaked information into the AFC system. Conversely, feeding “MORE HYPOCRISY: Obama Banned all Iraqi Refugees for 6 Months in 2011 – Liberals SAID NOTHING” into the AFC system would introduce unreliable and false information. These problems are under-researched but crucial for achieving realistic and effective fact-checking.
“CREDible, Unreliable, or LEaked” (CREDULE) dataset assisting the detection of leaked and unreliable evidence
To address these challenges, we developed the “CREDible, Unreliable, or LEaked” (CREDULE) dataset by modifying, merging, and extending previous datasets such as MultiFC, PolitiFact, PUBHEALTH, NELA-GT, Fake News Corpus, and Getting Real About Fake News. The CREDULE dataset consists of 91,632 samples from 2016 to 2022, equally distributed across three classes: “Credible,” “Unreliable,” and “Fact-checked” (Leaked). Our criteria ensure balanced distributions not only across these classes but also across years, title length, and topics. The dataset includes both short texts (titles) and long texts (full articles), along with meta-data such as date, domain, URL, topic, and credibility scores. The credibility and bias scores were collected from the Media Bias / Fact Check organization.
After creating the CREDULE dataset, we developed the EVidence VERification Network (EVVER-Net), a neural network designed to detect leaked (fact-checked) and unreliable evidence during the evidence retrieval process. EVVER-Net can be integrated into an AFC pipeline to ensure that only credible and non-leaked information is used during training. The model leverages the power of large pre-trained Transformer-based text encoders, such as DeBERTa, CLIP, and T5 for short texts, and Long T5 and Longformer for long texts. It also integrates information from credibility and bias scores. EVVER-Net demonstrated impressive performance, achieving up to 89.0% accuracy without credibility scores and 94.4% with credibility scores.
Examining the evidence of widely used AFC datasets
Finally, we applied the EVVER-Net model to the evidence provided by several widely used AFC datasets, including LIAR-Plus, MOCHEG, FACTIFY, NewsCLIPpings, and VERITE. EVVER-Net identified up to 98.5% of items in LIAR-Plus, 95.0% in the “Refute” class of FACTIFY, and 83.6% in MOCHEG as leaked evidence. For instance, in the FACTIFY dataset, the claim “Microsoft bought Sony for 121 billion” was accompanied by the evidence: “A satire article claiming that Microsoft has bought Sony for 130 billion has gone viral […] the original article in a Spanish website was intended to be a prank. […]” which is sourced from a previously fact-checked article and directly provides the model with the answer curated by a professional fact-checker. This limits the model’s ability to detect and verify new claims that have not yet been fact-checked.
On the other hand, the NewsCLIPpings dataset had the lowest rate of leaked evidence at 14.1%, followed by our own VERITE at 35.3%. For instance, a claim from VERITE: “An image shows a large crowd gathered on the Rio de Janeiro seafront to celebrate a Mass delivered by Pope Francis in 2013” is accompanied by evidence “Pope Francis wraps up Brazil trip with Mass for 3 million”, which is sourced by CBS News and is correctly identified as credible by EVVER-Net. Another claim, “A photograph captured by NASA’s Mars Curiosity Rover on May 7, 2022, showed an artificial portal nearby.” is accompanied by evidence “Does This NASA Photo Show a ‘Portal’ and ‘Wall’ on Mars?” sourced by Snopes. The title by itself does not provide any leaked information into the model, but if the full article were to be fed into the model during training, it would reinforce the problem of leaked evidence.
While NewsCLIPpings and VERITE display significant improvements over other datasets in the field, there is still room for enhancement, as 20% of the evidence in these datasets was estimated to be non-credible. By utilizing EVVER-Net or similar architectures, the credibility of the evidence in NewsCLIPpings and VERITE could be further improved, helping to avoid the issues of unreliable and leaked evidence and overall, building and evaluating AFC pipelines in a more realistic manner.
References
Guo, Z., Schlichtkrull, M., & Vlachos, A. (2022). A survey on automated fact-checking. Transactions of the Association for Computational Linguistics, 10, 178-206.
Glockner, M., Hou, Y., & Gurevych, I. (2022, December). Missing Counter-Evidence Renders NLP Fact-Checking Unrealistic for Misinformation. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing (pp. 5916-5936).

The content of this post is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License (CC BY-NC-SA 4.0).
Papadopoulos Stefanos-Iordanis
AI Researcher
My main research interests lie in the areas of multimodal deep learning with a focus on multimedia verification and retrieval, such as automated multimodal misinformation detection and fact-checking.