Media Analysis, Verification and Retrieval Group
We are developing technologies and services for understanding, searching and verifying media content
We bring the power of AI into advanced multimedia content management solutions.
We develop methods and tools for bringing Trustworthy AI and advanced media analytics into new application settings and contexts.
Media Verification
We provide tools for image forensics, Exif metadata analysis, synthetic image detection, visual location estimation and video deepfake detection.
Content moderation
We have solutions for detecting Not Safe For Work (NSFW) and disturbing images and videos.
Video Search
We provide methods and services for reverse video search using audio-visual similarity on large collections of videos.
Media Asset Management
We have integrated a number of advanced computer vision and media retrieval methods into a complete web application that can serve diverse media asset management needs.

AI Bias Assessment and Mitigation
We offer methods and expertise on measuring and addressing bias and discriminatory behaviour in computer vision models.
Social Network Analysis
We offer tools and expertise on analysis and visualization of online social media connections, conversations and communities.
AI System Prototyping
We offer support for integrating cutting edge ΑΙ models into web services and end user applications.
Project Management
We have a long successful track record of research and innovation project coordination, and can provide consulting and research project management services.
Our software
The Media Verification team has extensive experience and expertise in the area of online disinformation with an emphasis on multimedia-mediated disinformation.
ViSiL
This repository contains the Tensorflow implementation of the paper Near-Duplicate Video Retrieval with Deep Metric Learning.
Created by
Giorgos Kordopatis-Zilos
Image Forensics
This is an integrated framework for image forensic analysis.
Created by
Markos Zampoglou
Computational Verification
A framework for “learning” how to classify social content as truthful/reliable or not. Features are extracted from the tweet text (Tweet-based features TF) and the user who published it (User-based features UB). A two level classification model is trained.
Created by
Olga Papadopoulou
Multimedia Geotagging
This repository contains the implementation of algorithms that estimate the geographic location of multimedia items based on their textual content. The approach is described in the paper Geotagging Text Content With Language Models and Feature Mining.
Created by
Giorgos Kordopatis-Zilos
Intermediate CNN Features
This repository contains the implementation of the feature extraction process described in Near-Duplicate Video Retrieval by Aggregating Intermediate CNN Layers. Given an input video, one frame per second is sampled and its visual descriptor is extracted from the activations of the intermediate convolution layers of a pre-trained Convolutional Neural Network. Then, the Maximum Activation of Convolutions (MAC) function is applied on the activation of each layer to generate a compact layer vector. Finally, the layer vector are concatenated to generate a single frame descriptor.
Created by
Giorgos Kordopatis-Zilos
Near-Duplicate Video Retrieval with Deep Metric Learning
This repository contains the Tensorflow implementation of the paper Near-Duplicate Video Retrieval with Deep Metric Learning. It provides code for training and evalutation of a Deep Metric Learning (DML) network on the problem of Near-Duplicate Video Retrieval (NDVR). During training, the DML network is fed with video triplets, generated by a triplet generator. The network is trained based on the triplet loss function.
Created by
Giorgos Kordopatis-Zilos
Our projects

MedDMO addresses the need of the European Digital Media Observatory (EDMO) to expand its regional coverage in EU countries and create a multinational, multilingual, and cross-sectoral hub focused on fact-checking, research, and education to counter disinformation in Malta, Greece and Cyprus. Several multimedia analysis tools are made available to assist fact-checkers and researchers in their work against disinformation. Media literacy activities and the organisation of awareness campaigns will be central to MedDMO, trying to build resilience and adaptability against disinformation among citizens and media in the Mediterranean region.
Dec 2022 – May 2025
Read more
MAMMOth aims at developing an innovative fairness-aware AI-data driven foundation that provides the necessary tools and techniques for the discovery and mitigation of multi-discrimination and ensures the accountability of AI-systems with respect to multiple protected attributes and for traditional tabular data and more complex network and visual data. The outcomes of research in MAMMOth will be made available both as standalone open-source components and integrated into an open source toolkit “MAMMOth toolkit”. The project also comprises active interaction with multiple communities of vulnerable and/or underrepresented groups in AI research, implementing a co-creation strategy to ensure that genuine user needs and pains are at the center of the research agenda.
Nov 2022 - Oct 2025
Read more
vera.ai seeks to build trustworthy AI solutions against advanced disinformation techniques, co-created with and for media professionals and set the foundation for future research in the area of AI against disinformation. Key novel characteristics of the AI models will be fairness, transparency (including explainability), robustness to new data, and continuous adaptation to new disinformation techniques.
Sep 2022 - Aug 2025
Read more
AI4Media aims to address the challenges, risks, and opportunities that the wide use of AI brings to media, society, and politics. The project aspires to become a centre of excellence and a wide network of researchers across Europe and beyond, with a focus on delivering the next generation of core AI advances to serve the key sector of Media.
Sep 2020 - Aug 2024
Read moreLatest News

MAI-BIAS toolkit for fairness analysis
MAI-BIAS is a toolkit for AI fairness analysis that was first created by the MAMMOth project. It aims to cover the needs of both computer scientists and auditors by bringing together existing and novel software solutions for AI bias detection and mitigation in a uniform interface. The toolkit can be installed either as a local runner -for fast bootstrapping in one machine- or as a tool for remote access through your organization’s infrastructure. Here is an introduction to the local runner counterpart, which is maintained by our team but also includes 40+ intra-organization module contributions. Those modules span various kinds of fairness analysis, trustworthiness analysis, recommendations for bias mitigation techniques, and dataset and model loading. New module contributions are always welcome.
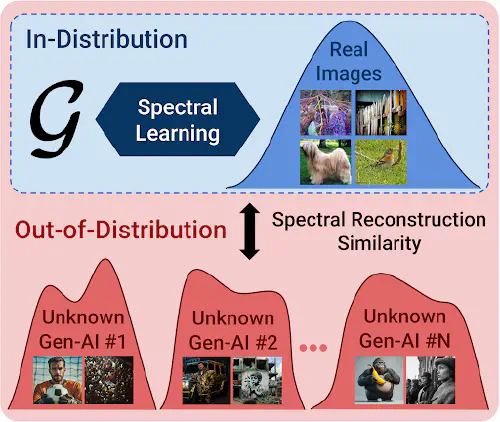
Any-Resolution AI-Generated Image Detection by Spectral Learning
AI-generated visual content already plays a prominent role in spreading disinformation across Europe. As the decrease in the cost of computational power enables sophisticated open-source models to be crafted and adapted with minimal effort, safeguards implemented by major AI providers, while helpful, cannot suffice for a robust long-term solution. Therefore, a major research question is how AI can also be employed to robustly distinguish AI-generated imagery from authentic one.
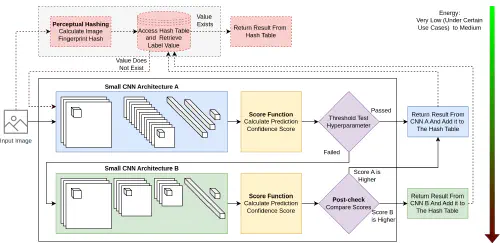
Reducing Inference Energy Consumption Using Dual Complementary CNNs
In this post we present our dual CNN methodology, that reduces inference energy requirements of CNNs in image classification tasks on low-resource devices. Further details about our approach and associated experiments are included in our paper Reducing inference energy consumption using dual complementary CNNs, which has been accepted for publication in the journal of Future Generation Computer Systems.