Video similarity based on audio
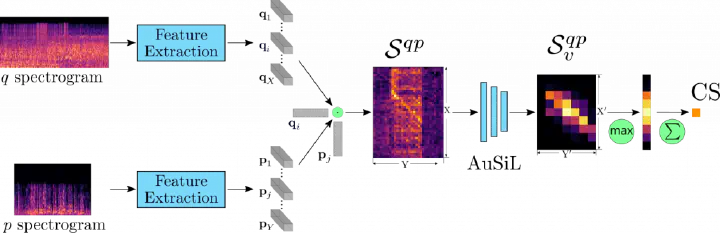 Figure by Giorgos Kordopatis-Zilos
Figure by Giorgos Kordopatis-Zilos
In this post, we explain the basics behind our paper “Audio-based Near-Duplicate Video Retrieval with Audio Similarity Learning,” which has been accepted for publication at this year’s International Conference on Pattern Recognition (ICPR 2020).
So, let’s consider the audio signals of two arbitrary videos as the ones displayed below. The left video serves as a query and the right as a target match.
To calculate the similarity between the two videos, we have to extract feature descriptors for the audio signals of the videos and then calculate the similarity between them as the final similarity score of the video pair. In this work, we have designed two processes that implement these functionalities: (i) a feature extraction scheme based on transfer learning from a pre-trained Convolutional Neural Network (CNN), and (ii) a similarity calculation process based on video similarity learning.
Feature extraction
Let’s begin with feature extraction. We employ the pre-trained CNN network designed for transfer learning. The network is trained on a large-scale dataset, namely AudioSet, consisting of approximately 2.1 million weakly-labeled videos from YouTube with 527 audio event classes.
To extract features, we first generate the Mel-filtered spectrogram from the audio of the videos. The audio signals are resampled at 44.1kHz sampling frequency. For the spectrogram generation, we use 128 Mel-bands and a window size of 23ms (1024 samples at 44.1kHz) with an overlap of 11.5ms (512 hop size). The generated spectrograms are divided into overlapping time frames of 2 seconds with t seconds time step.

Then, the generated spectrogram frames are fed to a feature extraction CNN that consists of seven blocks. Each block contains two convolutional layers, with batch normalization and ReLU activation, followed by a max-pooling layer. We extract a compact audio representation for each spectrogram frame by applying Maximum Activation of Convolutions (MAC) on the activations of the intermediate convolutional layers. In that way, we generate a vector representation for each audio frame. To improve the discriminative capabilities of the audio descriptors, we then apply PCA whitening and an attention-based scheme for the decorrelation and weighting of the extracted feature vectors respectively.

Similarity calculation
To measure the similarity between the two compared videos, we employ the video similarity learning scheme for the robust and accurate similarity calculation. More precisely, having extracted the audio representation of the two videos, we can now calculate the similarity between all the descriptor pairs of the two videos. In our example, let’s consider that our videos q, p have X, Y audio frames, respectively. We calculate the similarity between the feature vectors of the corresponding video descriptors by applying the dot product. In that way, we generate a pairwise similarity matrix , that contains the similarities between all vectors of the two videos.
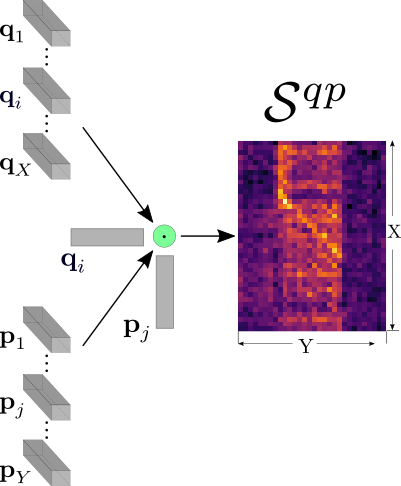
Then, to calculate the similarity between the two videos, we provide the refined pairwise similarity matrix to a CNN network, which we call AuSiL. The network captures the temporal similarity structures existing within the content of the similarity matrix, and it is capable of learning robust patterns of within-video similarities. In our examples, the network can detect temporal patterns and assign high similarity scores in the corresponding segments, i.e., the diagonal part existing in the center of the similarity matrix. At the same time, the noise in the input matrix, introduced by the similarity calculation process, has been significantly reduced in the output.

To calculate the final video similarity, we apply the hard tanh activation function on the values of the network output, which clips values within range [-1, 1]. Finally, we apply Chamfer Similarity to derive a single value, which is considered as the final similarity between the two videos.
Experimental results
For the evaluation of the proposed approach, we employ two datasets compiled for fine-grained incident and near-duplicate video retrieval, i.e., FIVR-200K and SVD. We have manually annotated the videos in the dataset according to their audio duplicity with the set of query videos. Also, we evaluate the robustness of our approach to audio speed transformations by artificially generating audio duplicates.
In the following table, we compare the retrieval performance of AuSiL against Dejavu, a publicly available Shazam-like system. The performance is measured based on mean Average Precision (mAP) on the two annotated datasets with two different settings, i.e., the original version and the artificially generated with speed transformation. AuSiL outperforms Dejavu by a considerable margin on three out of four runs. Dejavu achieves marginally better results on the original version of the FIVR-200K. It is evident that our approach is very robust against speed transformation, unlike the competing method.
For more details regarding the architecture and training of the model, but also for comprehensive experimental results, feel free to have a look at the AuSiL paper. The implementation of AuSiL is publicly available.
References
[1] Avgoustinakis, P., Kordopatis-Zilos, G., Papadopoulos, S., Symeonidis, A. L., & Kompatsiaris, I. (2020). Audio-based Near-Duplicate Video Retrieval with Audio Similarity Learning. arXiv preprint arXiv:2010.08737.
[2] Kumar, A., Khadkevich, M., & Fügen, C. (2018). Knowledge transfer from weakly labeled audio using convolutional neural network for sound events and scenes. In 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 326-330).
[3] Kordopatis-Zilos G., Papadopoulos S., Patras I., & Kompatsiaris, Y. (2017). Near-duplicate video retrieval by aggregating intermediate cnn layers. In international conference on Multimedia Modeling.
[4] Kordopatis-Zilos, G., Papadopoulos, S., Patras, I., & Kompatsiaris, I. (2019). ViSiL: Fine-grained spatio-temporal video similarity learning. In Proceedings of the IEEE International Conference on Computer Vision.

The content of this post is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License (CC BY-NC-SA 4.0).