Reducing Inference Energy Consumption Using Dual Complementary CNNs
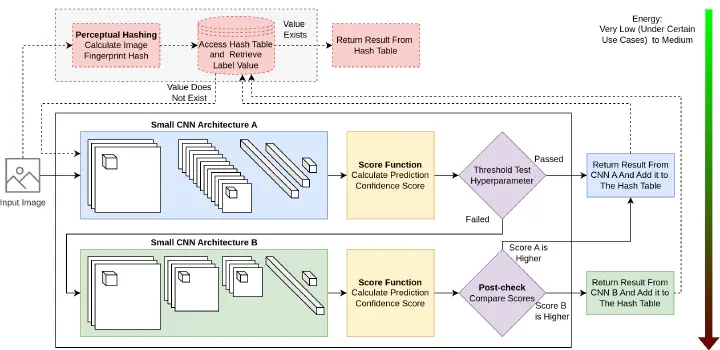 Overview of our proposed methodology, which consists of two complementary small CNN’s with a memory component.
Overview of our proposed methodology, which consists of two complementary small CNN’s with a memory component.
In this post we present our dual CNN methodology, that reduces inference energy requirements of CNNs in image classification tasks on low-resource devices. Further details about our approach and associated experiments are included in our paper Reducing inference energy consumption using dual complementary CNNs, which has been accepted for publication in the journal of Future Generation Computer Systems.
Introduction
Deep neural networks (DNNs) play a critical role in solving complex problems in smart environments, with growing applications in IoT, smart homes, and edge computing. However, deploying large DNNs on edge devices poses significant challenges due to their high energy demands, which can quickly deplete battery life and shorten device energy autonomy. Existing DNN compression techniques aim to address these issues by creating smaller models with fewer parameters and reduced computational requirements. While these methods enhance efficiency, they often come with trade-offs, including potential loss of accuracy and significant computational costs for re-training and fine-tuning. To address these limitations we propose a methodology that uses two small complementary CNNs, that combined they increased their predictive performance while still keeping energy consumption low.
Dual complementary CNN architecture
Our architecture consists of a pair of small convolutional neural networks (CNNs) that exhibit a relatively high complementarity score from a given pool of pretrained models. The selection process ensures that the two selected CNN models have the smallest size possible while together covering most of the prediction cases in a given dataset. This setup is further enhanced by the use of a caching mechanism that remembers previous similar classifications and skips the CNN inference if the same input is detected, leading to further energy reduction. For each input, the process begins with the first CNN generating a prediction and calculating a confidence score derived from its logits vector. An output logits vector of an artificial neural network represents the raw, unnormalized scores from the network’s final layer, where each value corresponds to a class in the dataset and indicates the relative likelihood of the input belonging to that class. This confidence score is then evaluated against a predefined threshold, which determines whether the second CNN needs to be activated. If the score falls below the threshold, the second CNN is invoked to refine the prediction. When both CNNs are utilized, their confidence scores are compared, and the final prediction is selected based on the higher confidence level. Additionally, with the memory component for every input, a unique fingerprint is generated and used as a key to access a hash table. If the hash table contains a stored classification for the fingerprint, the cached result is returned immediately, bypassing the need to invoke the CNNs leading to further energy reduction.
The Concept of Complementarity
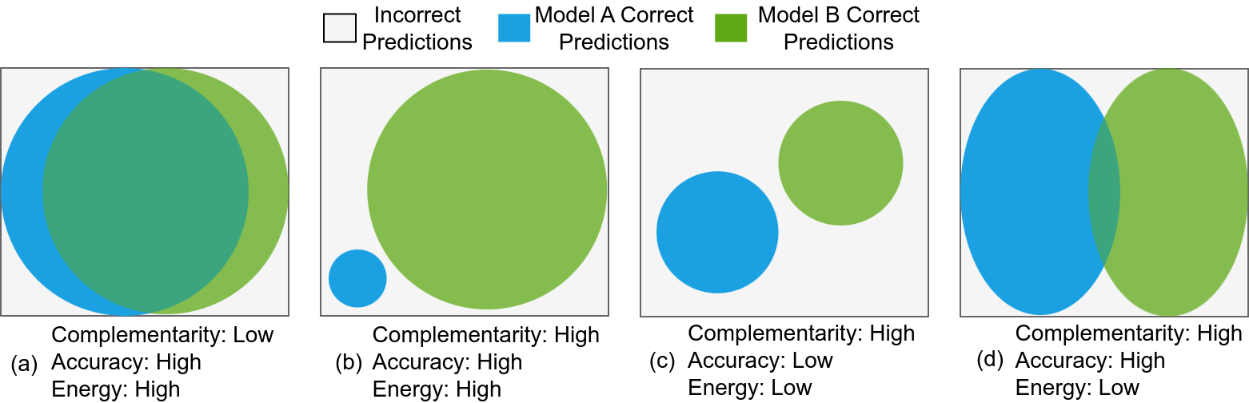
The concept of complementarity between two CNN models is illustrated using the above figure where the dataset is represented by a gray box, and the models’ correct predictions are depicted as blue and green circles. Complementarity is defined as the symmetric difference between the correct predictions of the two models, emphasizing their ability to complement each other’s strengths. Four scenarios highlight how complementarity impacts prediction performance and resource efficiency.
In the first scenario (a), both models correctly predict much of the dataset but overlap significantly, leading to low complementarity, redundancy, and higher energy consumption. The second scenario (b) shows high complementarity and extensive prediction coverage, but the larger model’s energy demands make the configuration inefficient. The third example (c) illustrates perfect complementarity with no overlap but limited prediction coverage, resulting in suboptimal accuracy. The fourth scenario (d) demonstrates the ideal balance, where models of similar size achieve high complementarity and cover most of the dataset with minimal overlap, optimizing both performance and resource utilization.
Results
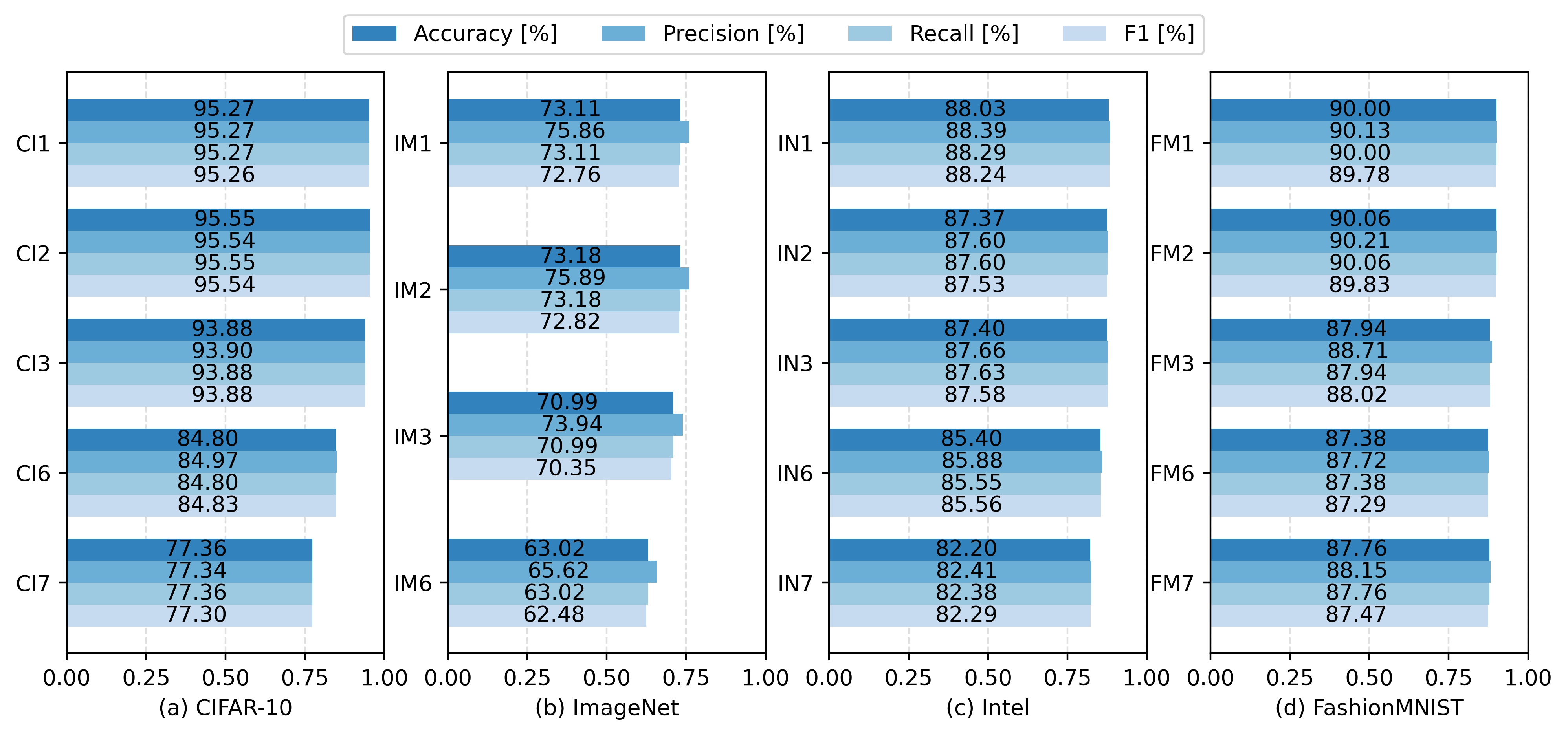
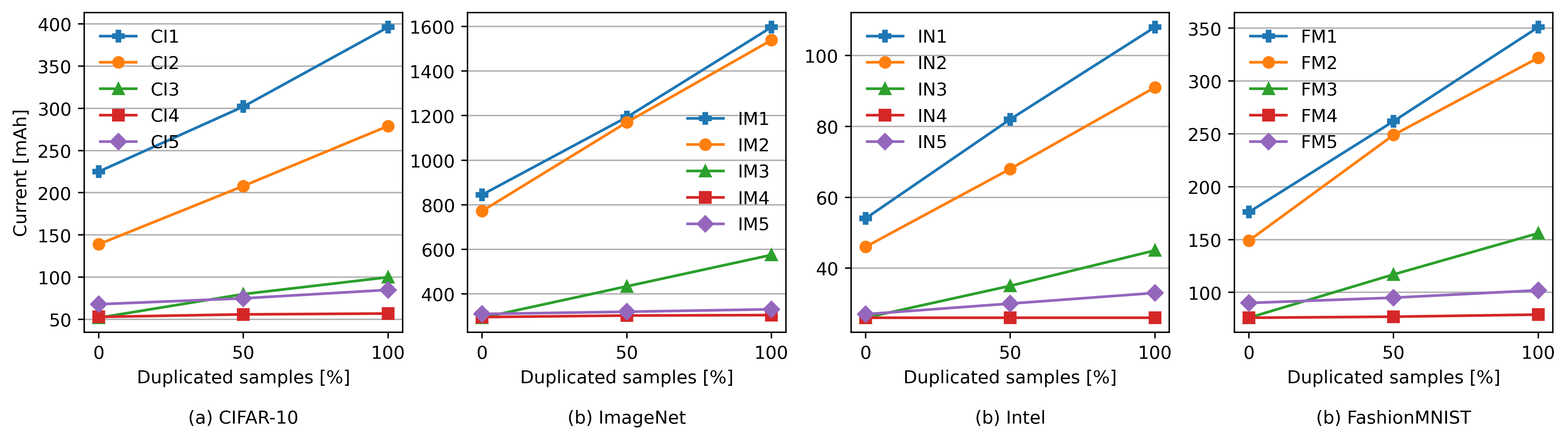
We conducted our experiments on four datasets: CIFAR-10, ImageNet, Intel Image Classification, and FashionMNIST. For each dataset, our architecture setups (CI3, IM3, IN3, and FM3, respectively) demonstrated reduced energy consumption while maintaining high accuracy. In contrast, other model compression techniques either achieved better performance at the cost of significantly higher energy consumption or reduced energy usage with substantial drops in accuracy. For more details on the other comparison methods you can read the paper here.
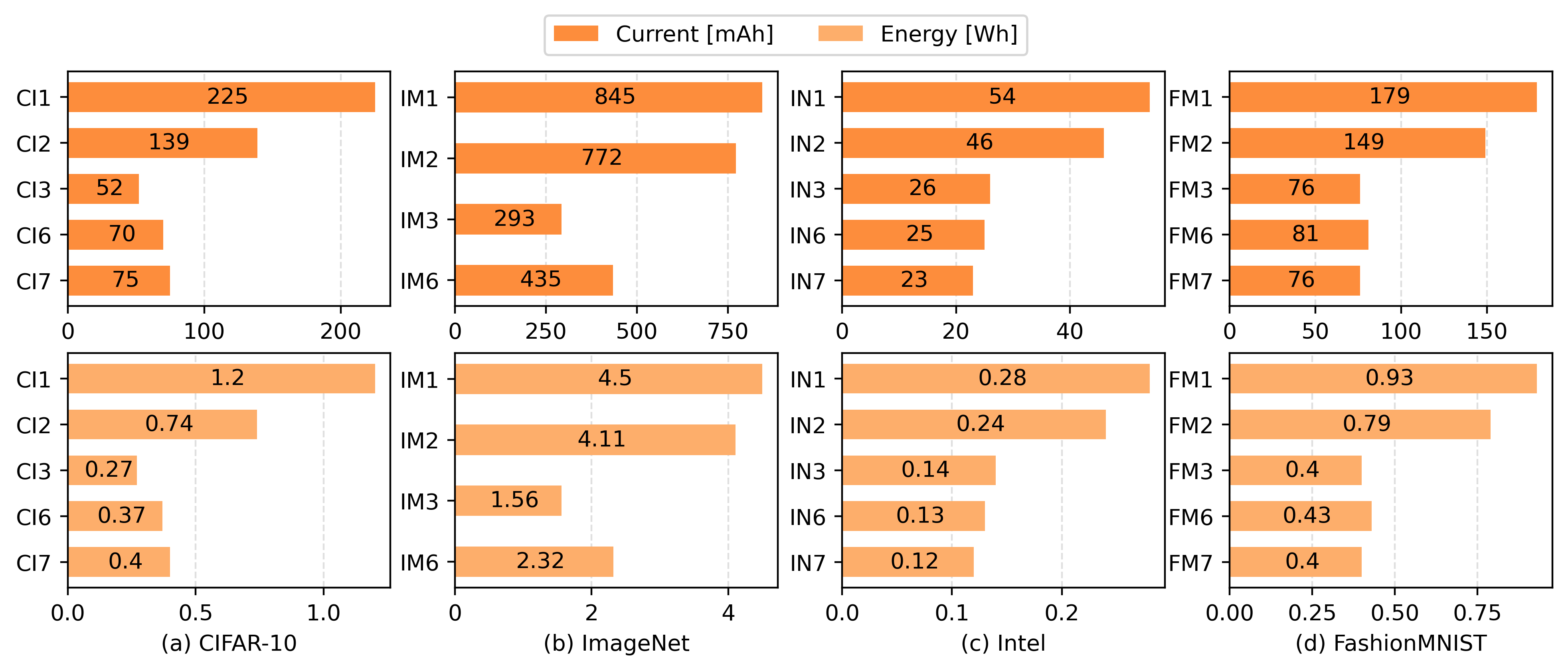
When utilizing the optional memory component, we observe significantly lower energy consumption in environments with repeated similar inputs. In the following figure, our implementations without the memory component are represented as CI3, IM3, IN3, and FM3, while those with the memory component (using two different methods) are labeled as CI4 and CI5, IM4 and IM5, IN4 and IN5, and FM4 and FM5. Notably, increasing the number of duplicated samples results in little to no additional energy consumption.
We also make available the code to reproduce our experiments on this GitHub repository.

The content of this post is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License (CC BY-NC-SA 4.0).
Kinnas Michael
Research Assistant
My main research interests lie in the areas of deep learning and computer vision.