Operation-wise Attention Network for Tampering Localization Fusion
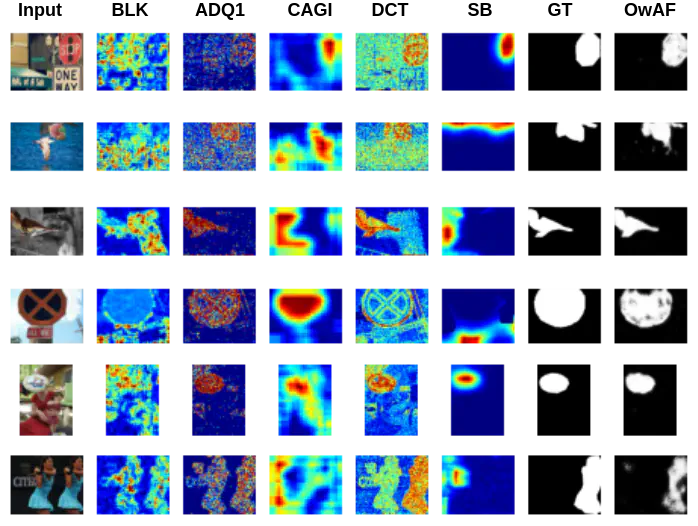 Various examples of tampering localization outputs using input images from the DEFACTO test dataset and fusion visualizations from the OwAF model (Ours); GT column refers to ground truth masks. Figure by Polychronis Charitidis
Various examples of tampering localization outputs using input images from the DEFACTO test dataset and fusion visualizations from the OwAF model (Ours); GT column refers to ground truth masks. Figure by Polychronis Charitidis
In this post, we explain the basics behind our paper “Operation-wise Attention Network for Tampering Localization Fusion”, which has been accepted for publication at this year’s Content-Based Multimedia Indexing conference (CBMI 2021).
The main motivation of this approach is to combine the outcomes of multiple image forensics algorithms and to provide a fused tampering localization map, which requires no expert knowledge and is easier to interpret by end users. Our fusion framework includes a set of five individual tampering localization methods for splicing localization on JPEG images:
- ADQ1 [1] and DCT [2] that both base their detection on analysis of the JPEG compression, in the transform domain.
- BLK [3] and CAGI [4] that base their detection on analysis of the JPEG compression in the spatial domain.
- Splicebuster [5], a noise-based detector selected as a complementary method due to its high reported performance and good interpretability of its produced outputs. To fuse the localization signals of the above algorithms, we adapt an architecture that was initially proposed for the image restoration task [6]. This architecture (OwAF) performs multiple operations in parallel, weighted by an attention mechanism to enable the selection of proper operations depending on the input signals. This weighting process can be very beneficial for cases where the input signal is very diverse, as in our case where the output signals of multiple image forensics algorithms are combined.
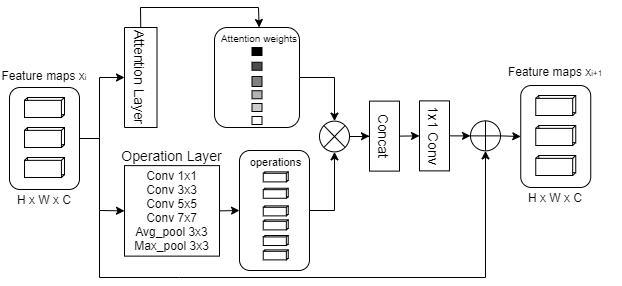
This architecture is suitable for our problem because it uses attention to capture important features by examining which operations are the most beneficial, depending on the input signal. Another important aspect of this architecture is that it can learn to attend low-level features, which is important for the fusion task, as semantic or high-level representations are often not relevant or useful for the problem. The network includes operations like, dilated convolutions, separable convolutions, and pooling with various kernel sizes and rates, which are weighted by an attention mechanism. To adapt this architecture to our needs, we replaced dilated convolutions with simple convolutions as the former are better suited for the image restoration task and exhibit lower validation performance in preliminary experiments.
For the model training in the fusion task, we generate a set of tampering localization outputs by applying the forensics algorithms for each image in the dataset. For this work, we use the DEFACTO dataset, which contains more than 150,000 images with synthetic forgeries and their corresponding ground truth masks. We randomly compile 15,000 images for training, 1000 for test, and 1000 for validation. For every input image in each set, we produce a set of tampering localization maps obtained by the selected detection methods. We evaluate the proposed deep learning models against the DEFACTO test dataset and two image forgery localization datasets, namely CASIA V2 and IFS-TC Image Forensics Challenge dataset. In the reported results besides the individual algorithms we also compared our method with another proposed architecture (Eff-B4-Unet) and another fusion framework (Iakovidou et al [7])
The OwAF model outperforms the Eff-B4-Unet in every evaluation metric for the DEFACTO test dataset. Evaluation results for individual algorithms are very low when compared to the fusion approaches. For the case of CASIA v2 we can observe that manipulations can be localized better by the individual algorithms. Regarding the fusion methods evaluation, our approach outperforms the competing fusion framework from Iakovidou et al. Regarding results on the First IFS-TC Image Forensics Challenge dataset, we observe a significant decrease in the performance of the individual algorithms with the exception of the Spicebuster algorithm, which even outperformed both fusion approaches.
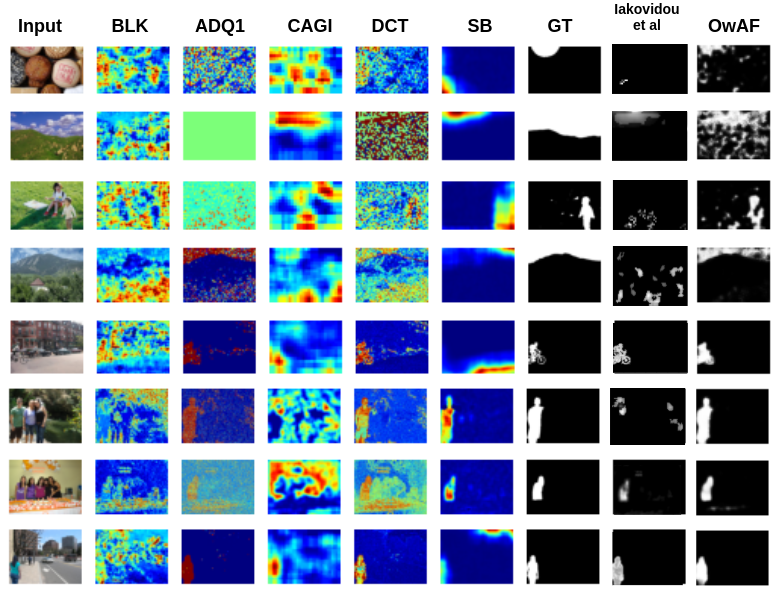
From our experiments, it is evident that the main challenge of the proposed approach stems from overfitting to the training data. Although OwAF can outperform individual forensics algorithms or other fusion models, we observe a lack of generalization to unseen manipulations. Namely, we get poor predictions for datasets that have different types of manipulations compared to those that appeared in the training dataset. Additionally, the low evaluation performance of individual models is an indication that the forgery localization problem is very challenging and it is even harder to design a general fusion solution for images in the wild.
References
[1] Z. Lin, J. He, X. Tang, and C.-K. Tang, “Fast, automatic and fine-grained tampered jpeg image detection via dct coefficient analysis,”Pattern Recognition, 2009. [2] S. Ye, Q. Sun, and E.-C. Chang, “Detecting digital image forgeries by measuring inconsistencies of blocking artifact,” in 2007 IEEE International Conference on Multimedia and Expo, 2007. [3] W. Li, Y. Yuan, and N. Yu, “Passive detection of doctored jpeg image via block artifact grid extraction,”Signal Processing, 2009. [4] C. Iakovidou, M. Zampoglou, S. Papadopoulos, and Y. Kompatsiaris,“Content-aware detection of jpeg grid inconsistencies for intuitive image forensics,” Journal of Visual Communication and Image Representation, 2018. [5] D. Cozzolino, G. Poggi, and L. Verdoliva, “Splicebuster: A new blindimage splicing detector,” in 2015 IEEE International Workshop onInformation Forensics and Security (WIFS), 2015. [6] M. Suganuma, X. Liu, and T. Okatani, “Attention-based adaptive se-lection of operations for image restoration in the presence of unknown combined distortions,” in Proceedings of the IEEE/CVF Conference onComputer Vision and Pattern Recognition, 2019. [7] C. Iakovidou, S. Papadopoulos, and Y. Kompatsiaris, “Knowledge-based fusion for image tampering localization,” inIFIP International Confer-ence on Artificial Intelligence Applications and Innovations, 2020.

The content of this post is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License (CC BY-NC-SA 4.0).