MeVer@ICCV2019
 ICCV 2019 - October 27 - November 2, 2019 in Seoul, Korea. Photo by Giorgos Kordopatis-Zilos.
ICCV 2019 - October 27 - November 2, 2019 in Seoul, Korea. Photo by Giorgos Kordopatis-Zilos.
The International Conference on Computer Vision (ICCV) is one of the major computer vision conferences, hosted by IEEE and CVF. Along with the Computer Vision and Pattern Recognition Conference (CVPR) and the European Conference on Computer Vision (ECCV), they are the three top tier conferences in the world in the field of computer vision.
The ICCV 2019 took place on October 27 – November 2, 2019 in Seoul, Korea. The venue that hosted the conference was COEX Convention Center, located in the Gangnam-gu district of Seoul. The main conference was held on October 29 – November 1, 2019, and many co-located workshops and tutorials took place on October 27, 28 and November 2, 2019.

The ICCV attracts the interest of a large number of scientists and researchers from all over the world, who present their recent advancements in fields related to computer vision. Also, it appeals to large companies, such as Google, Facebook, and Microsoft, but also well known universities from academia, such as Stanford University, MIT, and Oxford University.
This year’s event was chaired by Kyoung Mu Lee, Prof. at Seoul National University, David Forsyth, Prof. at the University of Illinois at Urbana-Champaign, Marc Pollefeys, Prof. at ETH-Zurich, and Tang Xiaoou, Prof. at the Chinese University of Hong Kong. In total, the ICCV 2019 counted 7,501 attendees, an increase of 2.4 times over the previous edition ICCV 2017. It received more than 4,300 papers (double the number of submissions received by the previous edition), of which 1,075 papers were accepted for publication (an acceptance rate of ~25%), and 200 papers were selected for oral presentation (just 4.6% of the submitted papers).

There was a wide variety of computer vision problems covered by the papers presented in the ICCV conference, and many of them related to the media generation and verification problems that are of interest for our team. For instance, the winning paper of the best paper award is titled ’SinGAN: Learning a Generative Model From a Single Natural Image’ and introduces a method to generate multiple images or short videos (GIFs) using just a single natural image. Additionally, several papers on related problems were presented, including image synthesis (Lin et al.; Zhai et al.), image/video inpainting (Ren et al.; Lee et al.), image/video translation (Liu et al.; Chan et al.), face swap/reenactment/de-identification (Nirkin et al.; Gafni et al.), deep fake/face manipulation detection (Rossler et al.; Wang et al.), videos/image retrieval (Tolias et al.; Jiand et al.), location estimation (Liu et al.; Cai et al.), etc.
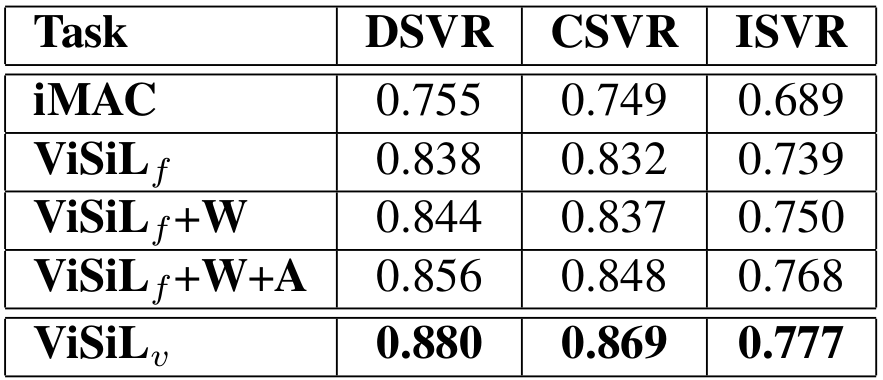
MeVer researcher Giorgos Kordopatis-Zilos presented our work with title ‘ViSiL: Fine-grained Spatio-Temporal Video Similarity Learning’. This work was developed within the WeVerify project. The main objective of this work is to devise a function that, given two arbitrary videos, generates a similarity score based on their visual content. This is the core functionality for a reverse video search system, which is often an essential tool for the task of media verification. More precisely, our goal is to learn a fine-grained similarity function that respects the spatial and temporal structures of videos, at the same time. This is achieved with a frame-to-frame function that respects the spatial within-frame structure of videos, and is then used to learn a video-to-video similarity function that also considers the temporal structure of videos. For more information, you can go through the paper or this simple blog post presenting the proposed method. The code and slides are available online on GitHub and SlideShare.

During the poster session, many experts in the fields of image/video retrieval and multimedia processing came by our poster. Most of the discussions focused on the in-depth explanation and the intuition behind our method, the possible extension of our method to related video detection problems (e.g., video copy detection, action localization), the combination or sole use of other modalities (i.e. audio) to perform video similarity calculation, and scalability issues of the present approach. These discussions were inspiring and gave us further ideas to expand our work in the future.

The content of this post is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License (CC BY-NC-SA 4.0).