MeVer participation in Deepfake detection challenge
 Deepfake Detection challenge promo image. Source: https://deepfakedetectionchallenge.ai/
Deepfake Detection challenge promo image. Source: https://deepfakedetectionchallenge.ai/
It has been almost 2 months since the final deadline for the challenge on the Kaggle platform. Competition organizers have just finalized the standings (13th of June 2020) in the private leaderboard. A Kaggle staff member mentioned in a discussion that competition organizers took their time to validate winning submissions and ensure that they comply with the competition rules. This process resulted in the disqualification of the top-performing team due to the usage of external data without proper license. This caused a lot of disturbance among the Kaggle community mainly because the competition rules were vague.
Performance evaluation on the challenge was measured with two leaderboards. The public leaderboard evaluation was performed using videos that share common characteristics with the training data that were provided by the competition and was available to participants throughout the challenge. On the other hand, the private leaderboard evaluation was performed on organic videos and various Deepfake manipulations that do not necessarily exist on training data and was revealed after the competition deadline
After the final rerankings, our team (which joined forces with DeepTrace) stands at the 115-th position on the private leaderboard, among 2,265 teams. The achieved Log Loss evaluation score is 0.51485. Note that our team stood at the 50-th position in the public leaderboard with a Log Loss score of 0.29502. It is apparent that our approach performs well on videos that originate from the same distribution as the training data and has relatively limited generalization ability. This observation applies to the large majority of submissions. For example, the winning team scored 0.20336 in terms of public validation score and only 0.42798 in the private leaderboard. Additionally, there were cases of severe overfitting on the training distributions. For example, the best submission in the public leaderboard scored 0.19207 in terms of Log Loss error, but in the private evaluation, the error was 0.57468 leading to the 904-th position in the private leaderboard.
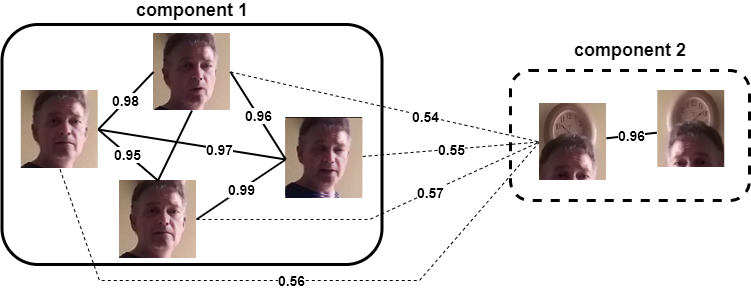
To deal with the DeepFake detection challenge, we focused on preprocessing the training data and used a deep learning approach that combined multiple architectures. The preprocessing step mainly involved dataset cleaning and generally increased the performance of our initial baseline models. More specifically, we used the MTCNN face detector to extract the bounding box information of all faces in video frames. Using the facial information we devised a similarity-based approach, which is shown in Figure 1, to cluster similar faces and remove false detections. Our preprocessing methodology is described in more detail here. Following this methodology, we managed to remove noisy detections and generate distinct face clusters from all frames of a video. Furthermore, we removed DeepFake videos that were very similar to original ones by calculating the face similarity among them and further balanced the dataset by sampling more frames from original videos. In practice, our final dataset consisted of real and fake face images. Real face images were sampled from approximately 20,000 real videos by uniformly extracting 16 frames per video. Fake face images were sampled from 80,000 fake videos by uniformly extracting 4 frames per video. Then, we resized the images to 300×300 and applied various augmentations such as horizontal and vertical flipping, random cropping, rotation, image compression, Gaussian and motion blurring, and brightness, saturation and contrast transformations.
We initially experimented with various deep learning architectures such as XceptionNet, MesoNet, InceptionResnet, etc. However, we noticed that EfficientNet outperformed all other architectures by a large margin. We decided to train EfficientNet-B3 and EfficientNet-B4 and although the latter scored better in the public leaderboard, a simple average of both architectures provided even better evaluation scores. For the inference pipeline, we uniformly extracted 40 frames per video and applied the preprocessing methodology we devised for the training data. Each detected face in a video could contain up to 40 face frames for inference. To get the aggregated prediction for each face, we averaged the individual predictions of all frames and models. Finally, we output the maximum prediction among the detected faces in a video. To exploit the temporal nature of videos, we also experimented with the I3D model. We used the I3D model just like the EfficientNet models, meaning that we made predictions at frame level with the difference that the I3D model used as input 10 consecutive frames instead of 1. By adding I3D to our ensemble and averaging individual frame and model predictions we managed to further increase the performance in the public leaderboard. This was our final model that finished in the 115-th position on the private leaderboard.
With the help of DeepTrace, we also experimented with an audio architecture but this did not appear to improve the performance of the model. Additionally, we tried various other techniques from the related bibliography (residual filters, optical flow, etc.) but none of them seemed to lead to further improvements for this task.
Although not every top-performing approach has been released so far, there are a lot of approaches among the top 50 that have been discussed online. Some common practices included the following:
The EfficientNet architecture and its variants were admittedly the best for this task. Most approaches combined EfficientNet architectures (B3-B7) and some of them were trained with different seeds. ResNeXT was another architecture used by a top-performing solution combined with 3D architectures such as I3D, 3D ResNet34, MC3 & R2+1D. Input image resolution varied from 256 to 380 among these approaches. Also, several approaches increased the margin of the detected facial bounding box. In our methodology, we used an additional margin of 20% but other works proposed a higher proportion. To improve generalization apart from strong augmentations like the ones we employed, some approaches proposed domain-specific augmentations like half face removal horizontally or vertically or landmark (eyes, nose, or mouth) removal. Additionally, the solution that was ranked third on the private leaderboard, reported that mixup augmentation further increased the generalization of the detection model. Finally, almost all approaches calculated frame-level predictions and aggregated them for final prediction. Finally, label smoothing seemed to improve the performance of some architectures.
Overall the competition was a valuable experience and we learned a lot along the process. We would also like to thank the DeepTrace team for the cooperation and exchange of knowledge. From our side, the main observation from the outcomes of the competition is that the Deepfake detection problem is far from solved and the generalization capabilities of modern deep learning approaches are still limited. We have already deployed our approach as a DeepFake detection API within the WeVerify platform to test the authenticity of online media and we will focus on further improving it in the future.

The content of this post is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License (CC BY-NC-SA 4.0).