Identifying image provenance in the wild
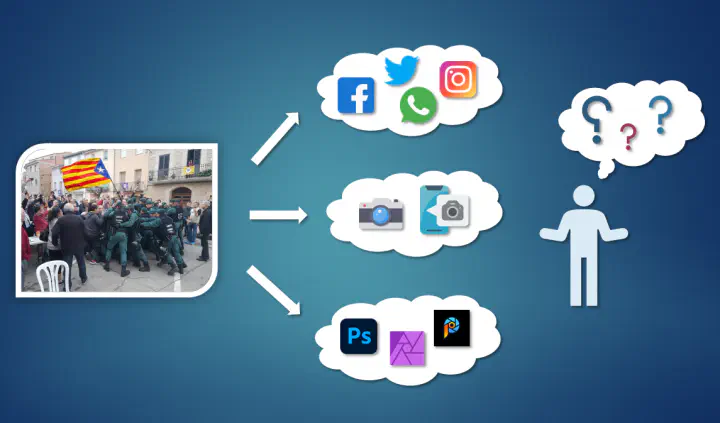 A common problem when examining a controversial image from the web is to find out who or what processed the image last. For example, an image may originate directly from a camera device, may have been shared to a social media platform or processed by some software. Image by Dimitris Karageorgiou.
A common problem when examining a controversial image from the web is to find out who or what processed the image last. For example, an image may originate directly from a camera device, may have been shared to a social media platform or processed by some software. Image by Dimitris Karageorgiou.
In the era of smartphones and social media, where everyone is able to capture the moment and share it online in seconds, knowing the origin of an image could make the difference between early debunking of a fabricated story and the continued spread of a false message. In this blog post, we will take a look at the task of identifying the source of an image, a key problem in the field of image provenance analysis. Also, we will present our findings on how most of the big digital platforms modify the popular JPEG standard and how we use these traces for identifying the source of images that circulate online without any prior knowledge or assumption.
The problem of image source identificationis in fact a long-standing one, challenging the people in the field of image forensics since the days digital photography started dominating the market. For example, one of the first considerable works in the area, attempting to identify the model of the camera used for shooting an image, dates back to 2004 [1]. Following this work, various ideas have been proposed for tackling the same problem. The former mainly attempted to model the artifacts introduced by the image capture pipeline of each camera, ranging from the popular PRNU noise pattern [17] introduced by the imperfections of the camera sensor to the artifacts generated by the color filter array (CFA) [2]. However, in recent years the field has mostly moved to deep-learning based approaches, using state-of-the-art neural network architectures, like the RemNet [3].
However, the issue of source identification is not limited to finding the camera model used in shooting an image. An image may as well have been posted to various social media platforms or processed by an image editing software. In the field of online media forensics [4], knowing the platform an image was uploaded to could be invaluable for tracking a disinformation campaign. Also, evidence that it was processed with some image editing software, like Adobe Photoshop, could turn suspicions that its contents have been tampered into certainty. For the former case, the image forensics community has presented a great amount of work that deals with the problem of source social media platform identification, like the work by Karunakar et al. (2021) [16]. On the other hand, we have seen a very limited amount of works that consider in some way the identification of the software used in tampering an image, like the more than decade old by Kornblum (2008) [12]. Instead, most of the available algorithms focus on localizing the tampered area of an image, like the ones provided by the image verification assistant.
Furthermore, as Pasquini et al. (2021) [4] have noticed, many works in the source identification field are only able to discriminate between specific camera devices, without the ability to generalize for example to the rest of the devices of the same model. Mandelli et al. (2022) [18] stated that this happens because most of these works utilize device-specific artifacts, like the popular PRNU pattern [17]. While these works could be useful in a juridical case, in the field of online media forensics it is rarely the case to have access to the specific camera device used in shooting a controversial photo.
From closed-set to open-set identification
Another aspect of the source identification task is the scope it is performed on. Most of the relevant works, regardless of the type of source they aim to identify, assume that all the possible sources are known beforehand and limit the task into selecting one of them. In reality, that means the possible options are limited to the ones contained in the datasets explored during the development of each work. This scenario is known as closed-set source identification and the latest algorithms seem to achieve accuracies easily exceeding 90%, as presented in the work of Mandelli et al. (2022) [18]. However, in real-world media forensics, knowing the possible sources of an image beforehand is almost never the case.
Due to the fact that an image found in the wild may have been captured by any smartphone or digital camera ever produced, modified by any of the available image editing software and shared through any of the existing social media platforms, some new ideas have emerged, attempting to deal with the task of open-set source identification, like the ones by Júnior et al. (2019) [5] and Lorch et al. (2021) [6]. The approaches taken in these cases ultimately attempt to answer two successive questions. The initial one is to decide whether the image under investigation comes from a set of known sources or not. Then, if the image has been found to originate from the group of known sources, the task is to attribute it to a specific source of the group, ultimately solving the closed-set problem. However, the evaluation of these algorithms has been primarily performed using the same available datasets, by hiding some of the included sources during the training phase, in an effort to model the group of unknown sources. So, considerable questions still remain on how well these methods would perform when having to deal with the much greater diversity encountered in the wild.
Identification of multiple types of sources
Multiple works in the field have relied primarily on the image signal for identifying the source. Also, the most sophisticated ones attempt to handle the unwanted artifacts introduced by subsequent stages in the lifetime of an image, in order to correctly identify the desired type of source. For example, Sarkar et al. (2020) [8] proposed a technique more robust against the effects introduced by sharing an image to a social network platform, in order to correctly detect the source camera model. Others have attempted to identify the sequence of social media platforms an image may have been shared on, like Phan et al. (2019) [19] However, common ground on all of them is their intention to identify only a single type of source, e.g. only the camera or social network of origin. A key problem missed by these approaches is the ability to identify the last actor that operated on an image independently of its type (camera, social media platform, image editing software etc.), which could be an invaluable tool when tracking disinformation campaigns and examining images found on the web.
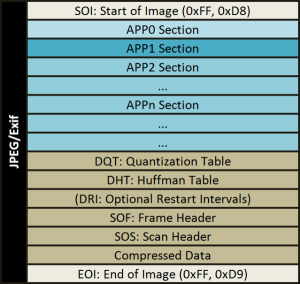
In a different approach, Mullan et al. (2019) [7] showed that the information contained in the JPEG header is a powerful tool for estimating the source of an image, heavily characterizing the software stack used during compression. Also, the JPEG format currently dominates the industry, with the majority of digital cameras using it for saving the photos, while more than 3 out of 4 websites contain JPEG images.
If some of the JPEG header data could be attributed with high certainty to some sources, this would allow deterministically attributing to their last source a great amount of the images that circulate on the web without a need for sophisticated signal processing.
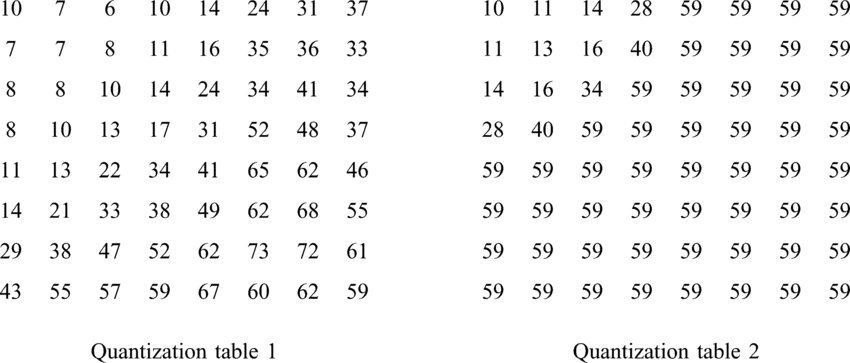
The JPEG quantization tables
The JPEG standard [9] defines a whole pipeline for compressing an image. The applied operations include among others the conversion of the image into the YCbCr colorspace, the splitting of it into 8×8 blocks, the application of the discrete cosine transform on each of them and the quantization operation. During quantization the 64 values inside each 8×8 block are divided by the values contained in an 8×8 quantization table and the decimal part of the results is stripped off. This process allows reducing the number of bits required for representing each frequency of the image by discarding some information, considering that the human eye is much more sensitive to some frequencies than others. Greater numbers in the quantization table mean that more information is discarded. Thus, the selection of the table greatly affects the quality of the compressed image. However, the standard itself does not define a specific table. Instead, it allows the users to use any tables suiting their needs and stores them into the header of the image. Also, different tables can be used for the quantization of each channel of the colorspace.
A very common set of quantization tables is the one proposed by the Independent JPEG Group (IJG) for use in its libjpeg library, which many image software have adopted, so, as of today, it is considered as the standard one. The set is based on two tables, one for the luminance channel (Y) and one for the chrominance channels (Cr, Cb), which can be scaled, according to a provided formula, into 100 different quality levels.
Based on the significance of the quantization table on image quality, it has been a long time since many companies in the photo industry, like digital camera and software brands, have started developing their own tables, tailored to the needs of their products. That for example means, a photo taken with a Canon camera would be distinguishable from another one taken with a Sony camera and both would be distinguishable before and after being edited with Adobe Photoshop in terms of their quantization tables. Farid (2006) [11] and Kornblum (2008) [12] were among the first to notice that the quantization table could be exploited for the purpose of source identification. However, they both focused only on a set of digital cameras of their era and on Adobe Photoshop.
Quantization tables in the imaging industry
In today’s image forensics, we still face the question on whether the use of quantization tables could be expanded for deterministically detecting images originating from popular social media platforms. Initially, given some older reports by Sun et al. in 2017 [13], stating that many popular social media platforms, including Facebook and Twitter, were utilizing only the IJG’s tables, we had limited hope. We could also verify that claim by examining the VISION [14] dataset, which also dates back to 2017 and contains photos from multiple smartphones before and after being published to various social media platforms.
However, moving on to the most recent publicly available dataset we were aware of, the FODB [15] which was released in 2020, we encountered a largely different situation. Images of 4 out of the 5 included social media platforms, namely Facebook, Instagram, Twitter and WhatsApp, were using custom quantization tables.
Regarding smartphones, we also had signs of a similar trend. In VISION, we had noticed that only 2 out of the 11 manufacturers of the included models were utilizing their own quantization tables. On the other hand, in FODB, almost half of the included smartphone manufacturers were using non-standard tables.
However, a big issue for our research was that even the most recent publicly available datasets mostly contained devices announced more than five years ago. We clearly could not rely on such data for framing the current situation of the market. So, we collected image samples for the 50 most popular smartphone models of 2021 and 2022 according to CounterPoint’s report and Flickr’s popularity index. Examining those data, we found out that brands previously using their own quantization tables continued in the same way, while brands that previously did not, like Xiaomi, Redmi and Google, started doing so.
Additionally, from past works we already knew that digital camera and image editing software brands were among the first adopters of custom quantization tables. However, due to the age of these works, we had to revisit these areas to get a more accurate picture of today. So, we collected image samples for models of the top 8 camera brands in Flickr’s index. Also, we thoroughly examined all the export modes available to popular image editing software, including Adobe Photoshop, Corel PaintShop Pro and Serif Affinity Photo.
Regarding digital cameras, we could not find a single model to not utilize manufacturer specific tables. Some brands, like Canon, use the same single table in multiple models, so it can clearly identify the manufacturer. Others, like Panasonic, seem to introduce some adaptivity to their table selection mechanism, which however generates a limited variety of tables, able to identify even some specific camera models.
Finally, all of Adobe Photoshop, Corel PaintShop Pro and Serif Affinity Photo, utilize brand-specific tables. Especially in Photoshop, every single export mode utilizes Adobe’s own tables. So, if an image comes with them, we know that it has been processed in some way.
So, we concluded that most big brands in the tech industry have introduced their own quantization tables in their products, which can be used for identifying the source of an image, in pretty acceptable granularities. Also, this trend seems to rise, since companies that previously were relying on the standard tables, are now starting to use their own.
Enhancements to the Image Verification Assistant
According to the findings we presented, we have updated the Image Verification Assistant, in order to be able to identify the source of images acquired in the wild, without any prior knowledge or assumption about their provenance. The assistant is able to identify the provenance of an uploaded photo in the following cases:
- social media platforms, namely Facebook, Instagram, WhatsApp and Twitter,
- image editing software and libraries, including Adobe Photoshop, Corel PaintShop Pro and Serif Affinity Photo,
- smartphones from the top brands in the market,
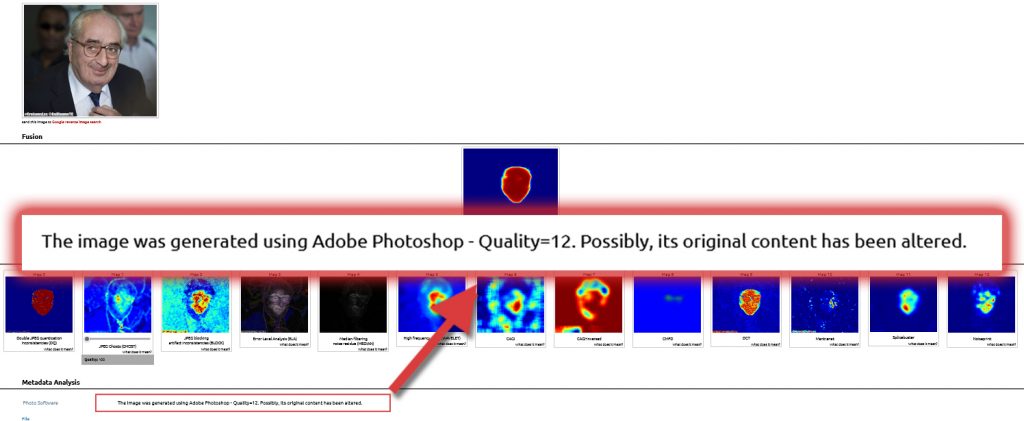
- digital cameras from all the established brands in the industry. Based on our insights, the updated Image Verification Assistant is able to estimate the source of almost 80% of the submitted images with non-standard quantization tables. This should be considered a significant step forward from the previous version which could hardly exceed 20%. Below, we see the Assistant having detected the software that last processed a tampered image and the settings used for exporting it.
References
[1] Weyand, T., Kostrikov, I., & Philbin, J. (2016). Planet-photo geolocation with convolutional neural networks. In European Conference on Computer Vision (pp. 37-55).
[1] Kharrazi, M., Sencar, H. T., & Memon, N. (2004). Blind source camera identification. In 2004 International Conference on Image Processing, 2004. ICIP’04. (Vol. 1, pp. 709-712). IEEE.
[2] Cao, H., & Kot, A. C. (2010). Mobile camera identification using demosaicing features. In Proceedings of 2010 IEEE International Symposium on Circuits and Systems (pp. 1683-1686). IEEE.
[3] Rafi, A. M., Tonmoy, T. I., Kamal, U., Wu, Q. M., & Hasan, M. (2021). RemNet: remnant convolutional neural network for camera model identification. Neural Computing and Applications, 33(8), 3655-3670.
[4] Pasquini, C., Amerini, I., & Boato, G. (2021). Media forensics on social media platforms: a survey. EURASIP Journal on Information Security, 2021(1), 1-19.
[5] Júnior, P. R. M., Bondi, L., Bestagini, P., Tubaro, S., & Rocha, A. (2019). An in-depth study on open-set camera model identification. IEEE Access, 7, 180713-180726.
[6] Lorch, B., Schirrmacher, F., Maier, A., & Riess, C. (2021). Reliable Camera Model Identification Using Sparse Gaussian Processes. IEEE Signal Processing Letters, 28, 912-916.
[7] Mullan, P., Riess, C., & Freiling, F. (2019). Forensic source identification using JPEG image headers: The case of smartphones. Digital Investigation, 28, S68-S76.
[8] Sarkar, B. N., Barman, S., & Naskar, R. (2021). Blind source camera identification of online social network images using adaptive thresholding technique. In Proceedings of International Conference on Frontiers in Computing and Systems (pp. 637-648). Springer, Singapore.
[9] Wallace, G. K. (1991). The JPEG still picture compression standard. Communications of the ACM, 34(4), 30-44.
[10] Neelamani, R., De Queiroz, R., Fan, Z., Dash, S., & Baraniuk, R. G. (2006). JPEG compression history estimation for color images. IEEE Transactions on Image Processing, 15(6), 1365-1378.
[11] Farid, H. (2006). Digital image ballistics from JPEG quantization.
[12] Kornblum, J. D. (2008). Using JPEG quantization tables to identify imagery processed by software. digital investigation, 5, S21-S25.
[13] Sun, W., & Zhou, J. (2017). Image origin identification for online social networks (OSNs). In 2017 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC) (pp. 1512-1515). IEEE.
[14] Shullani, D., Fontani, M., Iuliani, M., Shaya, O. A., & Piva, A. (2017). VISION: a video and image dataset for source identification. EURASIP Journal on Information Security, 2017(1), 1-16.
[15] Hadwiger, B., & Riess, C. (2021). The Forchheim image database for camera identification in the wild. In International Conference on Pattern Recognition (pp. 500-515). Springer, Cham.
[16] Karunakar, A. K., & Li, C. T. (2021). Identification of source social network of digital images using deep neural network. Pattern Recognition Letters, 150, 17-25.
[17] Lukas, J., Fridrich, J., & Goljan, M. (2006). Digital camera identification from sensor pattern noise. IEEE Transactions on Information Forensics and Security, 1(2), 205-214.
[18] Mandelli, S., Bonettini, N., & Bestagini, P. (2022). Source Camera Model Identification. In Multimedia Forensics (pp. 133-173). Springer, Singapore.
[19] Phan, Q. T., Boato, G., Caldelli, R., & Amerini, I. (2019). Tracking multiple image sharing on social networks. In ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 8266-8270). IEEE.

The content of this post is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License (CC BY-NC-SA 4.0).
Karageorgiou Dimitris
Multimedia Forensics Researcher | Software Engineer
My main research interests span the areas of multimedia forensics, content retrieval, artificial intelligence, and distributed software architectures. In charge of the R&D process for the Image Verification Assistant and the Near Duplicate Detection services.