How similar are two videos?
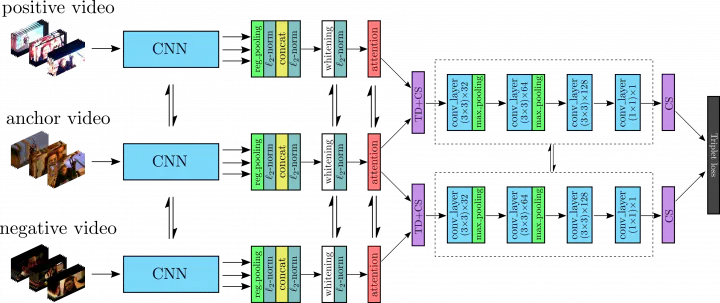 Figure by Giorgos Kordopatis-Zilos
Figure by Giorgos Kordopatis-Zilos
In this post we explain the basics behind our paper with title “ViSiL: Fine-grained Spatio-Temporal Video Similarity Learning” [1] which was accepted for an oral presentation at this year’s International Conference on Computer Vision (ICCV 2019).
Let’s consider two arbitrary videos, such as the ones displayed below. Also, we consider that the right video serves as query and the left as a candidate match. For the better understanding of the method, we select two near-duplicate videos.

To calculate the similarity between the two videos, we can extract global feature descriptors for the frames of the video [2, 3], and then calculate the frame-to-frame similarity matrix from the dot products between each frame pair, as displayed below.
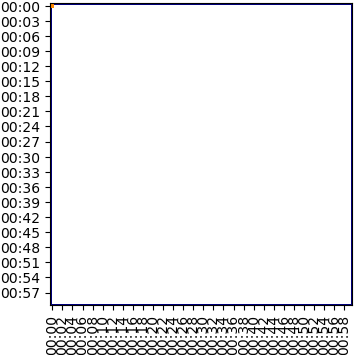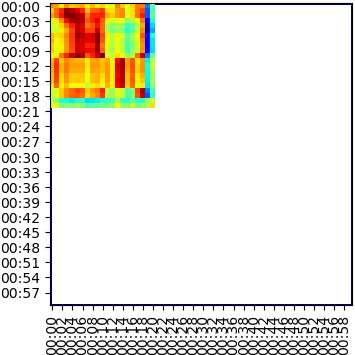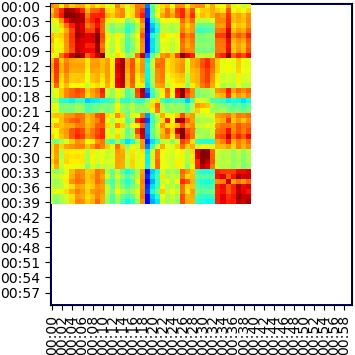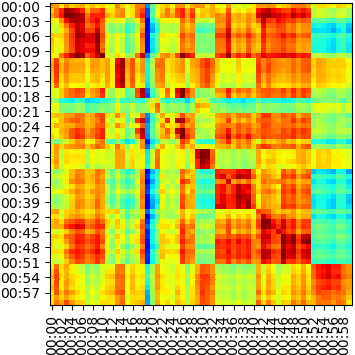
The video-to-video similarity score can be measured using Chamfer Similarity (CS), which we empirically found to capture well the similarity between videos. This is calculated as the average similarity of the most similar frames in the candidate video for each frame of the query. The mathematical formula is:

where, is the frame-to-frame similarity matrix, and and are the number of frames of each video. CS is robust against the different lengths of the candidate videos since it is calculated according to the query. For example, consider two candidates that contain the query in their entirety, and the second one is much longer video than the first one. Due to CS, they will have approximately the same video similarity to the query, which is handy for ranking videos for content-based video retrieval.
However, this scheme has several issues. First, the feature extraction process aggregates all frame information in a single vector representation resulting in a frame-to-frame similarity matrix with a lot of noise. Second, the CS function completely disregards the temporal structure of the frame-to-frame similarity matrix. Hence, we have to design a similarity calculation process that is able to introduce the least possible noise, and at the same time capture and model the temporal structure for the calculation of the video similarity.
To cope with these limitations, we introduce ViSiL, a Video Similarity Learning architecture that considers fine-grained spatio-temporal relations to calculate similarity between pairs of videos. ViSiL is trained to calculate video-to-video similarity from refined frame-to-frame similarity matrices, so as to consider both intra- and inter-frame relations.
Feature extraction
Let’s begin with feature extraction. Instead of aggregating the entire frame in a vector representation, we feed frames to a CNN and extract frame feature maps , based on Regional Maximum Activation of Convolution (R-MAC) [2] from the intermediate convolutional layers [3]. Also, we can consider that the extracted feature maps consist of



To improve the discriminative capabilities of the frame descriptors, we apply PCA whitening on the region vectors in order to decorrelate them. The following figure illustrates the 2D projection of a sample of region vectors before and after whitening. We can observe that after whitening, the vector distribution has a spherical form which facilitates the similarity calculation step.
Additionally, for more accurate similarity calculation, we want to focus on the information-rich part of the frames, and ignore the regions that contain no meaningful object (e.g. solid dark regions). To do so, we weigh frame regions based on their saliency via a visual attention mechanism over regions. This relies on an internal context vector that is applied on each region vector independently to generate the attention weights. The attention results on an arbitrary video are displayed below. In this example, the network apply high weights on the frame regions of the concert stage, and low ones on the completely dark regions.

Frame-to-frame similarity
Having extracted the region vectors of the frames of two videos, we can now calculate the frame-to-frame similarity between all the frame pairs of the two videos. To do so, for two video frames, we calculate the dot product between every pair of region vectors which creates a region-to-region similarity matrix. Then, we apply CS on the output similarity matrix to compute the frame-to-frame similarity for the given frame pair. The following figure depicts the process for the frame-to-frame similarity calculation.
This process leverages the geometric information captured by region vectors and provides some degree of spatial invariance. More specifically, the CNN extracts features that correspond to mid-level visual structures, such as object parts, and combined with CS, that by design disregards the global structure of the region-to-region matrix, constitutes a robust similarity calculation process against spatial transformations, e.g. spatial shift. This can be perceived as a trade-off between the preservation of the frame structure and invariance to spatial transformations.
The following figure illustrates the frame-to-frame similarity matrix from the initial calculation scheme and the refined one based on our method. It is evident that a lot of noise has been suppressed and the diagonal parts in the refined matrix are more clear than in the initial one. This leads to more accurate video-to-video similarity calculation.
Video-to-video similarity
Finally, to calculate the similarity between two videos, we provide the refined frame-to-frame similarity matrix to a CNN network in order to capture and highlight temporal similarity structures. The network is capable of learning robust patterns of within-video similarities at segment level, and therefore further refine the similarity matrix. Below are displayed the input frame-to-frame similarity matrix and the ViSiL output.
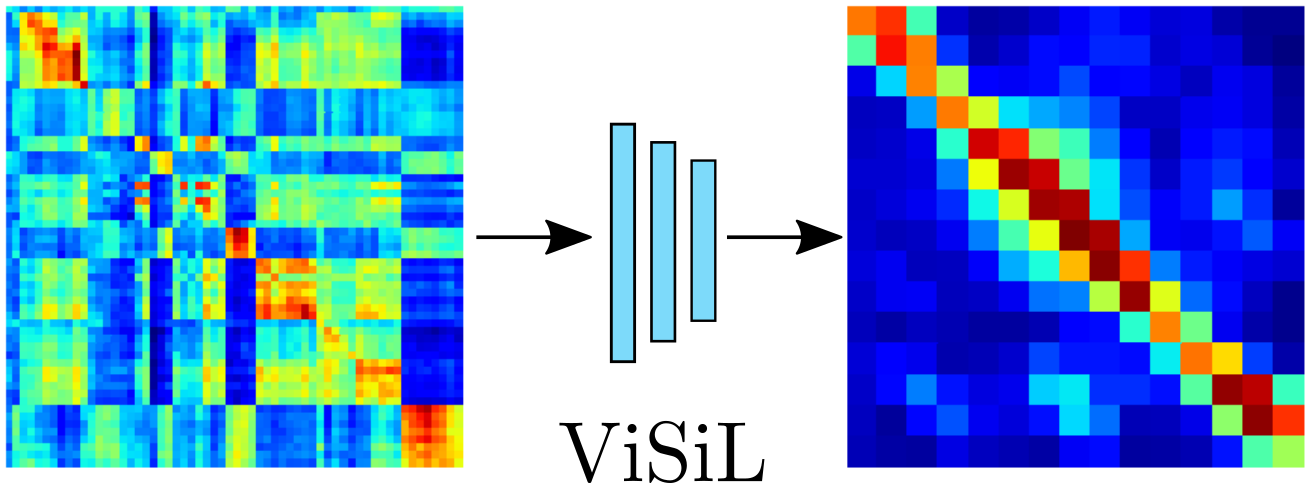
To calculate the final video-to-video similarity, we apply the hard tanh activation function on the values of the network output, which clips values within range [-1, 1], and then we apply CS to derive a single value which is considered the similarity between the two videos.
Similar to the frame-to-frame similarity calculation, this process is a trade-off between respecting video-level structure and being invariant to some temporal differences. As a result, different temporal similarity structures in the frame-to-frame similarity matrix can be captured, e.g. strong diagonals or diagonal parts (i.e. contained sequences).
Experimental results
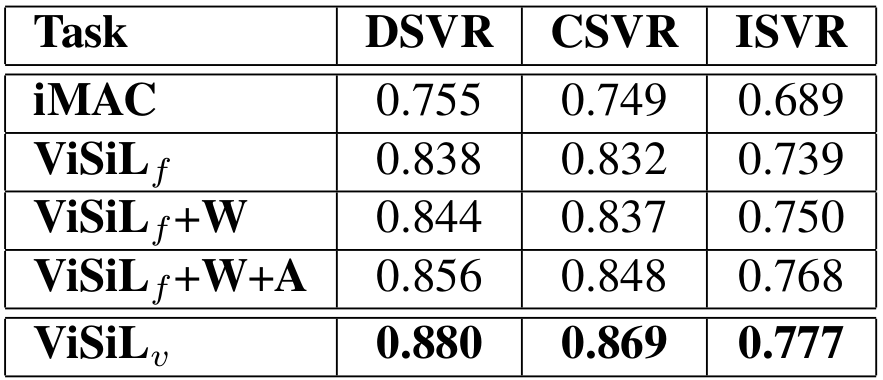
In the following table, we can find the results of the initial baseline scheme (iMAC) and four different versions of ViSiL in terms of mean Average Precision (mAP) on FIVR-5K (a subset of the recently published FIVR-200K video dataset [4]). ViSiLf, which is the version with only the presented frame-to-frame similarity and CS for video-to-video similarity, significantly outperforms the baseline. Also, the utilization of whitening and attention mechanism further improves performance. ViSiLv, which is the version with all the presented refinements, achieves the best performance with large margin.
Additionally, ViSiL achieved state-of-the-art performance on a number of retrieval problems, i.e. Near-Duplicate Video Retrieval (NDVR), Fine-grained Incident Video Retrieval (FIVR), Event Video Retrieval (EVR), and Action Video Retrieval (AVR). For more details regarding the architecture and training of the model, and for comprehensive experimental results on the four retrieval problems, feel free to have a look at the ViSiL paper [1]. Also, the implementation of ViSiL is publicly available.
References
[1] Kordopatis-Zilos G., Papadopoulos S., Patras I., and Kompatsiaris, Y. (2019). ViSiL: Fine-grained Spatio-Temporal Video Similarity Learning. arXiv preprint arXiv:1908.07410.
[2] Tolias G., Sicre R., and Jégou H. (2015). Particular object retrieval with integral max-pooling of CNN activations. arXiv preprint arXiv:1511.05879.
[3] Kordopatis-Zilos G., Papadopoulos S., Patras I., and Kompatsiaris, Y. (2017). Near-Duplicate Video Retrieval by Aggregating Intermediate CNN Layers. In International conference on Multimedia Modeling.
[4] Kordopatis-Zilos G., Papadopoulos S., Patras I., and Kompatsiaris, Y. (2019). FIVR: Fine-grained Incident Video Retrieval. IEEE Transactions on Multimedia.

The content of this post is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License (CC BY-NC-SA 4.0).