Geolocating images in the globe with high accuracy
 Visual examples of retrieved images based on our retrieval module, coloured based on their distance to the ground truth location of the query. The images are grouped based on the predictions of our retrieval and classification modules. Figure by Giorgos Kordopatis-Zilos
Visual examples of retrieved images based on our retrieval module, coloured based on their distance to the ground truth location of the query. The images are grouped based on the predictions of our retrieval and classification modules. Figure by Giorgos Kordopatis-Zilos
In this post we explain the basics behind our paper “Leveraging EfficientNet and Contrastive Learning for Accurate Global-scale Location Estimation” that has been accepted for publication at this year’s International Conference on Multimedia Retrieval (ICMR 2021).
The problem that we tackle in this work is the following: “Given an input image from anywhere in the world, estimate the coordinates of its geographic location, in terms of latitude and longitude, based solely on the visual information of the image.”
Typically, there are two types of approaches that try to solve the problem either as a classification problem or a retrieval one. The former partitions the earth’s surface into a grid of cells and then trains a classifier per cell to assign input images to it. The latter searches in a large-scale background database of geotagged images to retrieve similar ones based on a given image query and then aggregates them for estimating its location.
However, both formulations have limitations. The major drawback of classification approaches stems from the division of the earth into large geographic areas, which results in coarse estimations. On the other hand, retrieval-based approaches are more error-prone and need significantly more computational resources during inference.
This work aims to address these limitations and achieve high geolocation accuracy in all granularity scales. To this end, we build on the strong aspects of both classification and retrieval approaches based on our prior work on text-based geolocation. More precisely, we develop a Search within Cell (SwC) scheme, which consists of two modules, i.e., a classification and a retrieval one. An overview of our system is displayed below.
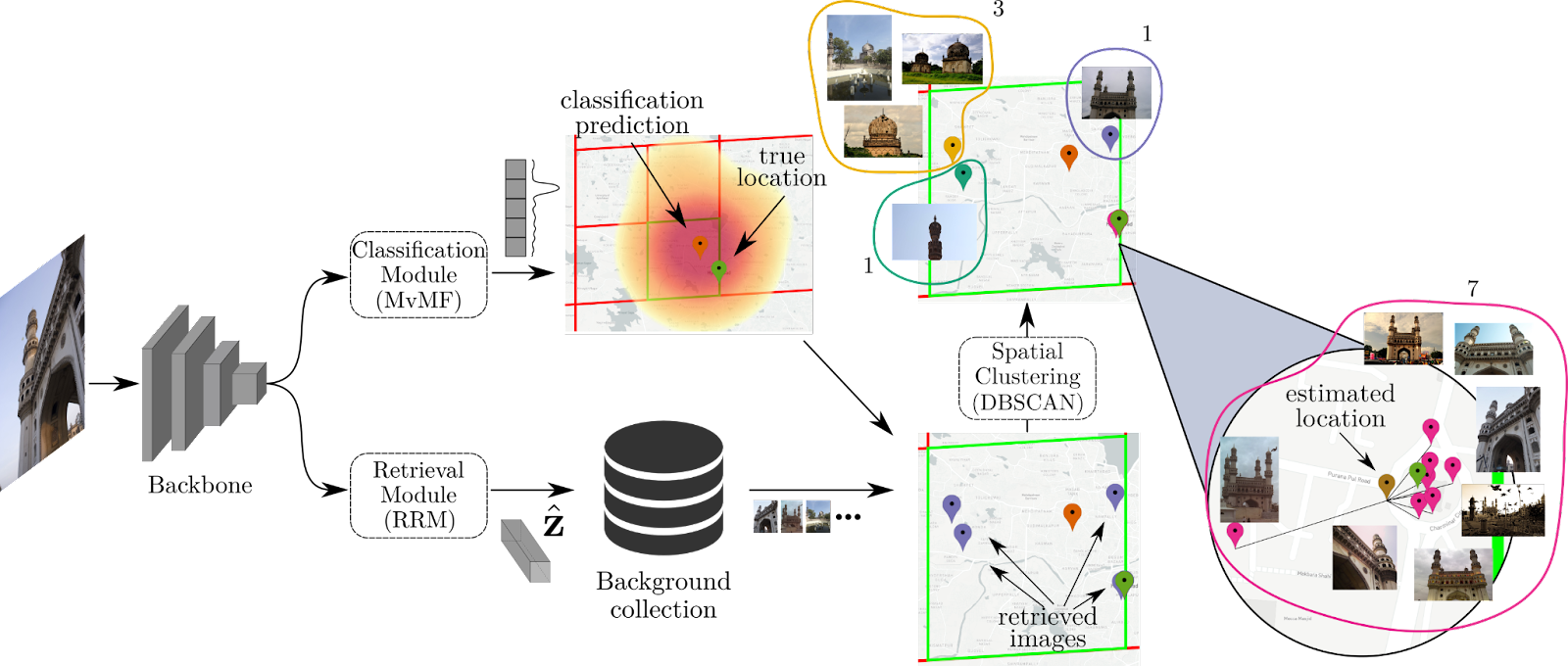
For the classification module, we first partition the earth’s surface into a grid of cells. Then, we employ EfficientNet, a state-of-the-art architecture, in order to map input images to a specific cell in the grid. We build the model based on a probabilistic approach of the geolocation task that uses a Mixture of von Mises-Fisher distributions (MvMF). The network is trained by minimizing the log-likelihood loss with a large corpus of geotagged images.
For the retrieval module, we first extract features for our images from the backbone CNN trained for the classification module, and then we feed them to a Residual Retrieval Module (RRM) that learns to map images to an embedding space where the images from the same location are closer to each other than the rest. We train our module based on the contrastive learning paradigm. Once we have trained our RRM module and extracted embeddings for our images, we can compute similarities and rank images from a database given a query.
Once we have both our modules trained, we employ a hybrid scheme to combine them, which we call Search within Cell (SwC):
-We perform classification to derive the cell with the largest probability. -We retrieve the top-most similar images of the background collection, with the constraint that the retrieved images fall within the borders of the estimated cell. -To enhance the robustness of the results, we develop a density-based spatial clustering scheme based on the DBSCAN algorithm, and we derive our final estimation, averaging the locations of the images that belong to the largest cluster.
We evaluate our approach on four benchmark datasets. Our method exhibits very competitive performance, significantly improving the state-of-the-art in many granularity ranges. In the well-known Im2GPS3K, we manage to geolocate 15% of the dataset images within 1km of their true location, and 30% of them within 25km. We also evaluate our method with various configurations to gain insight into its behaviour. For more details, we point readers to our paper.
Based on the developed approach, we have developed a web service. Please contact us if you are interested to try it out.
References
[1] Weyand, T., Kostrikov, I., & Philbin, J. (2016). Planet-photo geolocation with convolutional neural networks. In European Conference on Computer Vision (pp. 37-55).
[2] Hays, J., & Efros, A. A. (2008). Im2gps: estimating geographic information from a single image. In 2008 ieee conference on computer vision and pattern recognition (pp. 1-8).
[3] Kordopatis-Zilos, G., Papadopoulos, S., & Kompatsiaris, I. (2017). Geotagging text content with language models and feature mining. Proceedings of the IEEE, 105(10), 1971-1986.
[4] Tan, M., & Le, Q. (2019, May). Efficientnet: Rethinking model scaling for convolutional neural networks. In International Conference on Machine Learning (pp. 6105-6114). PMLR.
[5] Izbicki, M., Papalexakis, E. E., & Tsotras, V. J. (2019). Exploiting the earth’s spherical geometry to geolocate images. In Joint European Conference on Machine Learning and Knowledge Discovery in Databases (pp. 3-19). Springer, Cham.
[6] Chen, T., Kornblith, S., Norouzi, M., & Hinton, G. (2020). A simple framework for contrastive learning of visual representations. In International conference on machine learning (pp. 1597-1607). PMLR.

The content of this post is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License (CC BY-NC-SA 4.0).