FairBench
 FairBench: a library for comprehensive AI fairness exploration.
FairBench: a library for comprehensive AI fairness exploration.
As AI systems become more ingrained in everyday life, it is important to address fairness concerns. For example, machine learning models are known to pick up and exacerbate biases found in their training data. So far, various attempts have been made to quantify and mitigate unfair AI biases, for example with algorithmic frameworks like AIF360. However, these attempts tend to work on a case-by-case basis, with tackled measures of bias or fairness being restricted to simplistic settings, such as binary sensitive attributes (e.g., men vs women, whites vs blacks). For this reason, in the context of the Horizon Europe MAMMOth project we developed a Python library called FairBench to help system creators assess bias and fairness in complex scenarios.
About
FairBench is based on a simple workflow that enables principled exploration of AI system fairness while being flexible enough to accommodate the opinions of stakeholder in the social context where systems are deployed:
- Organizing multidimensional multivalue sensitive attributes and intersectional analysis into sensitive attribute forks. This way, one fork object represents all sensitive attributes, and it can be manipulated to create attribute intersections (such as “black women”) to be included in analysis.
- Using forks to generate fairness reports that compute many bias and fairness measures. Measures are built by combining many base building blocks; this goes beyond evaluating ad-hoc definitions of fairness and draws a bigger picture by considering as many of them as possible.
- Once potential issues are found by interacting with stakeholders, numerical computations can be backtracked to get a sense of where problems arise within fairness assessment computations.
- Extracting fairness model cards from reports that capture popular measures of bias and fairness, but which extract caveats and recommendations from a socio-technical database of considerations that is being created in MAMMOth.
The introductory design of FairBench was presented as an extended abstract at ECML PKDD BIAS 2023 | 3rd Workshop on Bias and Fairness in AI. The decomposition of literature measures of bias into smaller building blocks that can be combined to account for a wider range of settings was published in a paper titled “Towards Standardizing AI Bias Exploration” [1] that was presented in AIMMES 2024 | Workshop on AI bias: Measurements, Mitigation, Explanation Strategies.
Quickstart
After installing FairBench in a working environment with pip install --upgrade fairbench, a demonstration of the above pipeline looks like this:
import fairbench as fb
test, y, yhat = fb.demos.adult() # test is a Pandas dataframe
sensitive = fb.Fork(fb.categories @ test[8], fb.categories @ test[9]) # analyse the gender and race columns
sensitive = sensitive.intersectional() # automatically find non-empty intersections
report = fb.multireport(predictions=yhat, labels=y, sensitive=sensitive)
fb.interactive(report) # open a browser window in which to explore the report
stamps = fb.combine(
fb.stamps.prule(report),
fb.stamps.accuracy(report),
fb.stamps.four_fifths(report)
)
fb.modelcards.tohtml(stamps, file="output.html", show=True) # or tomarkdown, toyaml
FairBench can analyse several kinds of predictive tasks, such as classification, ranking, and regression tasks, the presence of which are determined from report method arguments. For example, a scores argument may be provided in the above snippet to also compute measures of bias and fairness that arise in recommender systems. Multiple tasks can be assessed simultaneously too. Several kinds of reports can be generated to suit different situations; each of these includes many (although not exhaustive) assessments. Report values and explanations can be accessed either programmatically or through an interactive exploration that looks like this:
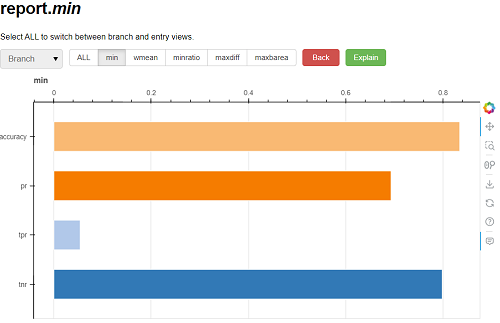
For more information, visit FairBench’s documentation. Pay special attention to how report columns encapsulate ways of comparing base performance measures between population groups or subgroups corresponding to sensitive attribute values; find these important explanations as part of the documentation. Finally, a tutorial for the library is available in YouTube.
Citations
- Emmanouil Krasanakis and Symeon Papadopoulos, “Towards Standardizing AI Bias Exploration”, 2405.19022 arXiv, 2024

The content of this post is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License (CC BY-NC-SA 4.0).
Krasanakis Emmanouil
Post-doctoral researcher
My main research interests lie in graph theory and graph neural networks, machine learning with focus on algorithmic fairness and discrimination, and software engineering.