Better, Faster and Lighter Video Retrieval
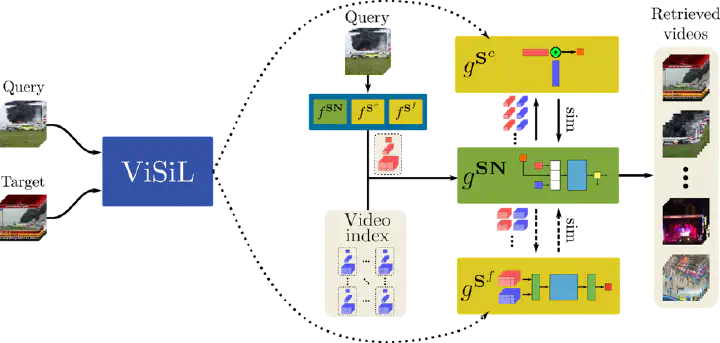 Overview of our Distill-and-Select approach. Having a high performance-low efficiency Teacher, i.e., our ViSiL network (in blue), we train a Coarse- and Fine-grained Student (in yellow) with Knowledge Distillation (indicated by the dotted lines) so as to mimic the Teacher’s behaviour. Also, a Selector Network (in green) decides whether the similarity calculated by the Coarse-grained Student is reliable or the Fine-grained one needs to be invoked. Figure by Giorgos Kordopatis-Zilos
Overview of our Distill-and-Select approach. Having a high performance-low efficiency Teacher, i.e., our ViSiL network (in blue), we train a Coarse- and Fine-grained Student (in yellow) with Knowledge Distillation (indicated by the dotted lines) so as to mimic the Teacher’s behaviour. Also, a Selector Network (in green) decides whether the similarity calculated by the Coarse-grained Student is reliable or the Fine-grained one needs to be invoked. Figure by Giorgos Kordopatis-Zilos
In this post, we explain the basics behind our paper “DnS: Distill-and-Select for Efficient and Accurate Video Indexing and Retrieval”, which has been accepted for publication in the International Journal of Computer Vision (IJCV).
Following our prior work in ViSiL, we realised that high-performing video retrieval systems require a significant amount of compute and storage resources. More precisely, our network achieved state-of-the-art performance on several video retrieval problems; however, it needed substantial time for similarity calculation and memory space for storing the video features.
To overcome this limitation, we have developed a reranking method called Distill-and-Select (DnS) that offers an excellent trade-off between performance and efficiency, leveraging Knowledge Distillation and devising a Selection Mechanism.
Our reranking system consists of three main networks: (i) a coarse-grained student () that provides very fast retrieval speed but with low retrieval performance, (ii) a fine-grained student () that has high retrieval performance but with high computational cost, and (iii) a selector network () that routes the similarity calculation of the video pairs and provides a balance between performance and time efficiency.

As displayed in the above figure, the processing can be split into two phases, i.e., Indexing and Retrieval. At indexing time, the feature representations of all videos in the database are extracted and stored in the video index. Each of our three networks extracts its corresponding representation, which is necessary for the retrieval phase. We use the notation for each network to denote the indexing process. At retrieval time, all possible query-target video pairs are sent by the selector network to the coarse-grained student so that their similarity is rapidly estimated. Considering the results and the self-similarity of the two videos, the SN takes a binary decision on whether the calculated coarse similarity needs to be refined by the fine-grained student, and for the small percentage of videos that this is needed, the fine-grained network calculates their similarity. Similarly, we use the notation for each network to denote the retrieval process.
In what follows, we will go through the basics regarding the training of the networks and the architectures employed for the teacher, students and selector networks.
Knowledge Distillation
Our goal here is to build a training process in order to train our student networks to mimic the behaviour of a well-performing teacher network and generate similarity scores that are close to the teacher’s. In that way, we can train several networks on different retrieval performance-computational efficiency trade-offs.

The training process is straightforward and displayed in the above figure. First, a video pair is selected by a large unlabeled dataset. Then, the teacher calculates the similarity between the two videos and generates their similarity score . Next, the student calculates its own similarity score between the two videos, and the loss is derived based on the difference between the scores generated by the teacher and the student as in:

Note that the loss is defined on the output of the teacher, which allows us to use any arbitrary unlabelled dataset for the training of our students.
Additionally, in this setting, the selection of the training pairs is crucial. Since it is very time-consuming to apply the teacher network to every pair of videos in the dataset ( complexity) and randomly selecting videos would result in mostly pairs with low similarity scores, we have devised a pair selection scheme to select pairs of interest.
Since our previous ViSiL network achieves state-of-the-art performance, we use it as a teacher to our framework. We have designed three students, two fine-grained and one coarse-grained variant, each providing different benefits. The fine-grained students are both using the ViSiL architecture. The first fine-grained student simply introduces more trainable parameters with a more complex attention scheme, leading to better performance with similar computational and storage requirements to the teacher. It is called fine-grained attention student (). The second fine-grained student optimises a binarization function that hashes features into a Hamming space and has very low storage space requirements for indexing with little performance sacrifice. It is called fine-grained binarization student (). Keep in mind that in our final DnS system, only one of the two fine-grained students is deployed as the network mentioned above. The third coarse-grained student learns to aggregate the region-level feature vectors based on a Transformer+NetVLAD network architecture in order to generate global video-level representations. It needs considerably fewer resources for indexing and retrieval but at a notable performance loss. It is called coarse-grained student ().
Selection Mechanism
This is a reranking process based on a selector network that judges whether the similarities of video pairs calculated by a coarse-grained student are reliable or need to be refined by a fine-grained student .
Typically, the similarity between two videos estimated by a fine-grained student leads to better retrieval scores than the one estimated by the coarse-grained student. However, for some video pairs, the difference between them is small, which has a negligible effect on the ranking and on whether the video will be retrieved. So, we use a selector network trained to distinguish between those video pairs and pairs of videos that exhibit large similarity differences.
The selector network is trained as a binary classifier with Binary Cross-Entropy (BCE) used as a loss function. We first derive video pairs from an unlabeled dataset, and their and similarities are calculated based on the coarse- and fine-grained students, respectively. Then, we obtain binary labels by setting a threshold for the difference between the two similarity scores:

The selector network gets as input the similarity calculated by the coarse-grained student and the videos of the pair in question. First, it processes each video independently in order to capture their self-similarities, using a modified ViSiL head. Then, these self-similarity scores are combined with the coarse-grained similarity through an MLP network to derive the confidence score , which is the final output of the selector.
As stated above, the selector network is trained with the BCE loss calculated based on its confidence score and the binary label derived from the label function.
During retrieval, the selector takes a binary decision based on its confidence score. If it is closer to 1, then the fine-grained student is invoked; otherwise, the similarity of the coarse-grained student is considered for the ranking.
Experimental results
The figure below displays the performance of our proposed DnS framework and its variants against several state-of-the-art methods in terms of retrieval performance based on mean Average Precision (mAP) on the DSVR task of FIVR-200K and efficiency based on the required time per query and storage space per video. Coarse-grained methods are in blue, fine-grained in red, and re-ranking in orange.
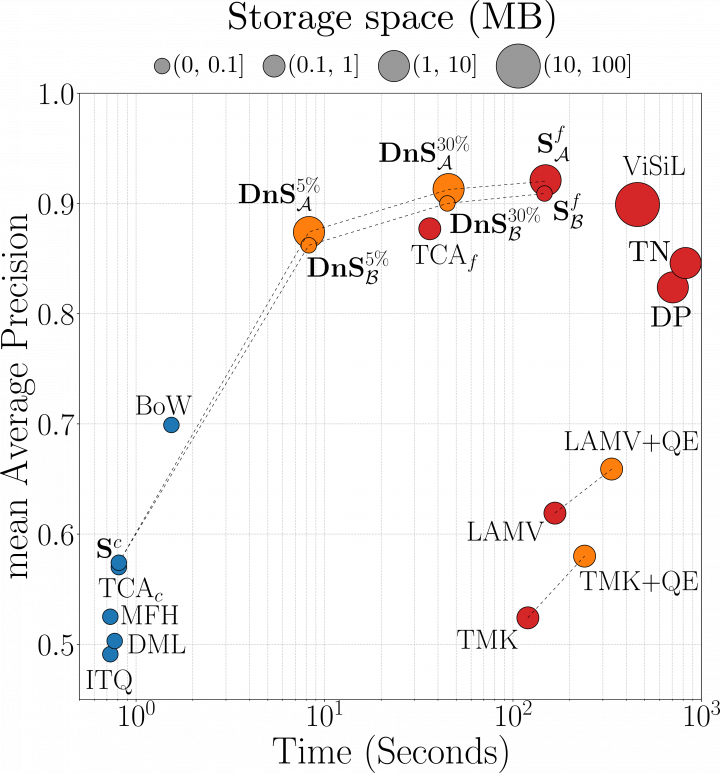
Our approaches achieve the best performance, requiring very little compute resources, especially in comparison to the ViSiL teacher network, which was the previous state-of-the-art. In particular, when the fine-grained binarization student is used with 5% of the dataset sent for reranking, our DnS method achieves 55 times faster retrieval with 230 times less storage space, with a minor drop of 0.03 in mAP compared to the ViSiL.
Additionally, DnS achieved very competitive performance on several other video retrieval datasets, i.e., the rest FIVR-200K tasks, CC_WEB_VIDEO, EVVE, and SVD. For more details regarding the network architectures, training of the models, and comprehensive experimental results, we point readers to our DnS paper. Also, the implementation of DnS is publicly available.
Based on the developed approach, we have developed a web service, a short demo of which is available in the video below. Please contact us if you are interested in trying it out.
References
[1] Kordopatis-Zilos G., TzelepisPapadopoulos S., Kompatsiaris, I, and Patras I. (2022). DnS: Distill-and-Select for Efficient and Accurate Video Indexing and Retrieval. arXiv preprint arXiv:2106.13266.
[2] Kordopatis-Zilos G., Papadopoulos S., Patras I., and Kompatsiaris, Y. (2019). ViSiL: Fine-grained Spatio-Temporal Video Similarity Learning. In International Conference on Computer Vision.
[3] Kordopatis-Zilos G., Papadopoulos S., Patras I., and Kompatsiaris, Y. (2019). FIVR: Fine-grained Incident Video Retrieval. IEEE Transactions on Multimedia, 2019.

The content of this post is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License (CC BY-NC-SA 4.0).