Any-Resolution AI-Generated Image Detection by Spectral Learning
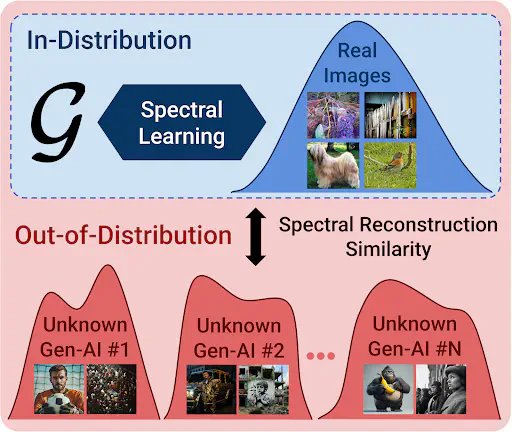 Figure 1: SPAI employs spectral learning to learn the spectral distribution of real images under a self-supervised setup. Then, using the spectral reconstruction similarity it detects AI-generated images as out-of-distribution samples of this learned model.
Figure 1: SPAI employs spectral learning to learn the spectral distribution of real images under a self-supervised setup. Then, using the spectral reconstruction similarity it detects AI-generated images as out-of-distribution samples of this learned model.
AI-generated visual content already plays a prominent role in spreading disinformation across Europe. As the decrease in the cost of computational power enables sophisticated open-source models to be crafted and adapted with minimal effort, safeguards implemented by major AI providers, while helpful, cannot suffice for a robust long-term solution. Therefore, a major research question is how AI can also be employed to robustly distinguish AI-generated imagery from authentic one.
While several approaches for detecting AI-generated images have emerged, their common issue is the inability to maintain consistent detection performance on images generated by models not considered during their training. Consequently, keeping them effective requires maintaining an elaborate training dataset, which, apart from needing significant human labor, could also be completely intractable, due to the countless available generative models. Key to this limitation is the popular belief that one could detect generated imagery by identifying a set of inconsistencies that are common for all generative models. However, to date, the image forensics community has yet to discover any universal theoretical limitation that would hold for any generative model. Instead, we constantly see weaknesses that were common in some early models, like the inability to generate clear text, to be fixed by newer ones, like in the case of Google’s Imagen.
To tackle this fundamental issue, we took a different path in our latest work. Instead of searching for general inconsistencies among the generated images, we opted to model the attributes of real images. We assume that the latter are not directly affected by the introduction of any single generative model, but primarily by long-term technological advances. Therefore, their distribution constitutes a more invariant pattern for the task of AI-generated image detection. In particular, we opted for the spectral distribution of real images, as recent literature has shown that the differences among real and AI-generated images are exceptionally visible in the spectral domain.
Given a model of the spectral attributes of real images, it would be possible to detect the generated as the ones that do not conform to this learned model, i.e. as out-of-distribution samples. However, it was neither clear how such a spectral model could be learned, nor how to detect its out-of-distribution samples. Therefore, we had to introduce both in our Spectral AI-Generated Image (SPAI) detection framework.
In SPAI, we employ a self-supervised setup to model the spectral distribution of real images. To achieve this, we use the pre-text task of frequency reconstruction. Then, to detect its out-of-distribution samples we introduce three learnable components. First, we hypothesize that the learned spectral model will better reconstruct the frequencies of the real images, i.e. its in-distribution samples. So, we introduce the concept of spectral reconstruction similarity to measure this reconstruction error. Next, we assume that the spectral information present in an image defines the importance of reconstruction errors for different frequency ranges. Thus, we craft the spectral context vector to capture the spectral context of the image. Finally, by introducing the spectral context attention mechanism we enable the efficient processing of any-resolution images without further pre-processing. This significantly increases the ability of a detector to capture subtle inconsistencies, crucial for classifying high-fidelity imagery. An overview of SPAI’s architecture is presented in Figure 2, while an in-depth technical analysis is available on our CVPR 2025 paper.
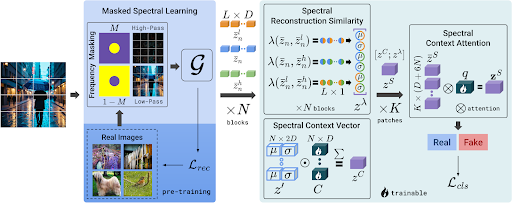
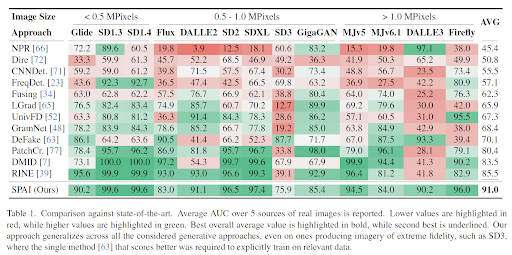
To evaluate the efficacy of SPAI, we composed a comprehensive benchmark of 13 recent generative approaches as well as real images originating from DSLR and smartphone cameras and the Web. As we see in Table 1, while previous detectors exhibit very high performance on specific GenAI models, they catastrophically fail on others. Instead, SPAI achieves consistently high detection performance across all the considered image generators.
In Figure 3, we see that SPAI is capable of distinguishing among AI-generated and real images independently of the depicted topic or visual aesthetics, highlighting its capability to not overfit specific image semantics.
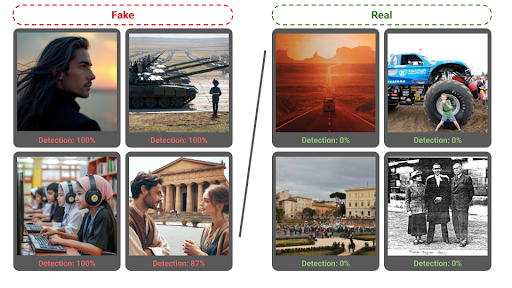
Moreover, the spectral context attention provides a built-in mechanism to explain which image regions were the most important for the final decision. For example, we see on Figure 4 that not only SPAI could correctly classify this Stable Diffusion 3 image but was also capable of identifying the 6-fingers inconsistency as important for this decision.

On the other hand, while SPAI significantly improves over the previous state-of-the-art approaches, we believe that it would be premature for any approach to claim fully solving this extremely complex task. For example, generated images frequently circulate in the form of derivative images, such as in screenshots, external photos of a screen or even printed material. In these cases, the intermediate medium significantly distorts the image signal and limits the performance of any detector solely relying on the image signal. Therefore, further research is necessary on combining spectral learning with contextual understanding.


As we remain committed to open research, we open-source SPAI, to enable AI practitioners and researchers to build upon it towards creating a sustainable AI-driven ecosystem of digital media.Check out our project page for the source code, trained weights and data of SPAI.
Our work was performed in close collaboration with the VIS lab of the University of Amsterdam and is included in the program of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2025 (June 11th-15th 2025 in Nashville, USA). For those not attending, you can check out our online presentation and contact us for any further questions.
We would like to thank the ELIAS and vera.ai Horizon Europe projects for actively supporting this effort, as well as GRNET for providing access to the required computational resources.

The content of this post is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License (CC BY-NC-SA 4.0).
Karageorgiou Dimitris
Multimedia Forensics Researcher | Software Engineer
My main research interests span the areas of multimedia forensics, content retrieval, artificial intelligence, and distributed software architectures. In charge of the R&D process for the Image Verification Assistant and the Near Duplicate Detection services.